#llama_cpp 搜索结果

【8GB VRAMでも爆速!】MOEモデルが皆さんのPCで動く!?驚異の #llama_cpp パフォーマンス!😳 「高価なGPUがないと生成AIは厳しい…」そんな常識、もう過去の話かもしれませんね! なんと8GB VRAMのGPUでも大規模なMOEモデルが驚きの速度で動作するベンチマーク結果が報告されましたよ!✨…


Running #LocalLLaMA fully local on my Android phone—no cloud BS. llama.cpp + Termux build. Shattered the mirror, speaking plain truth ~5-6 t/s phone-only inference, quantized & offline. Privacy god mode. Code/steps/prompts in thread #AndroidAI #llama_cpp #OnDeviceAI #LLMs
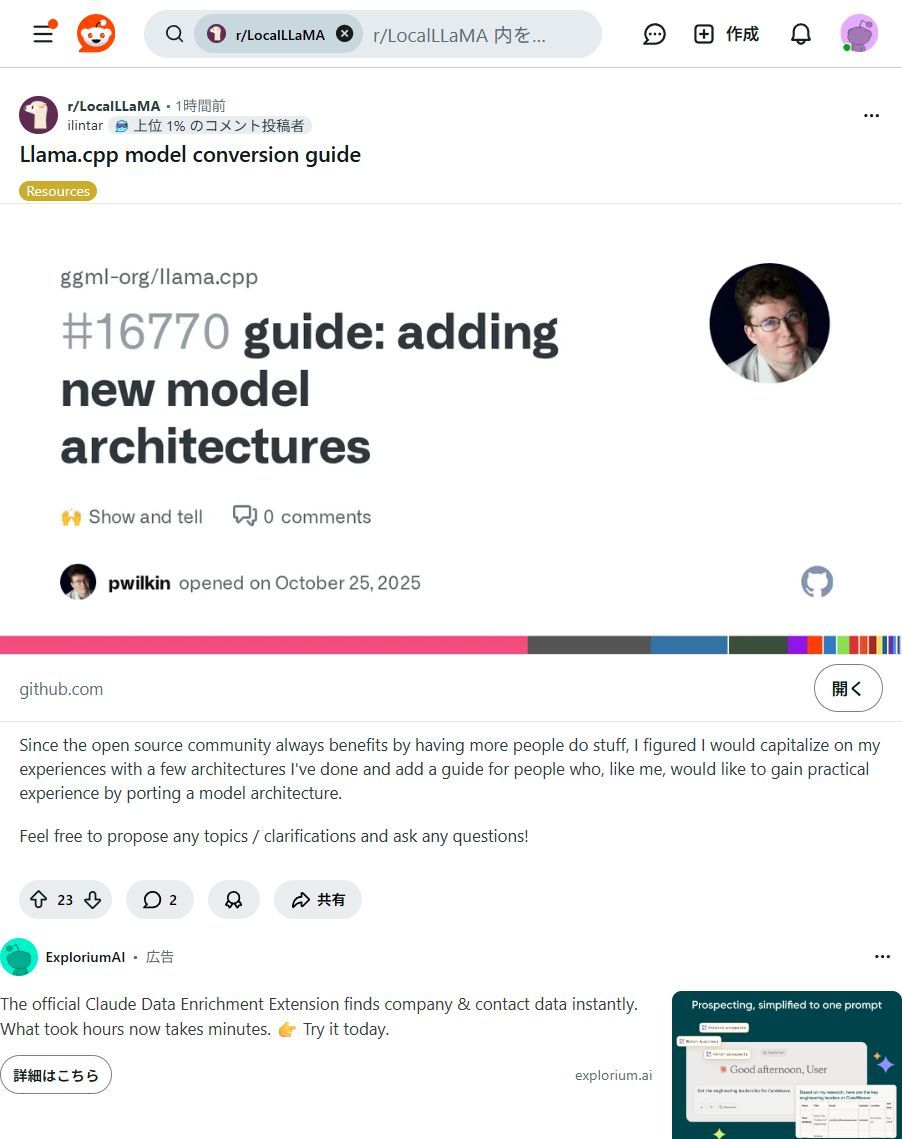
PCでAIモデルをもっと自由に!Llama.cpp活用ガイド登場✨ 最新AIモデルをローカルPCで動かす実践ガイド公開!クラウド費用削減、セキュリティ強化、カスタマイズが可能に。新しいAIの可能性を広げよう! #AIモデル #Llama_cpp
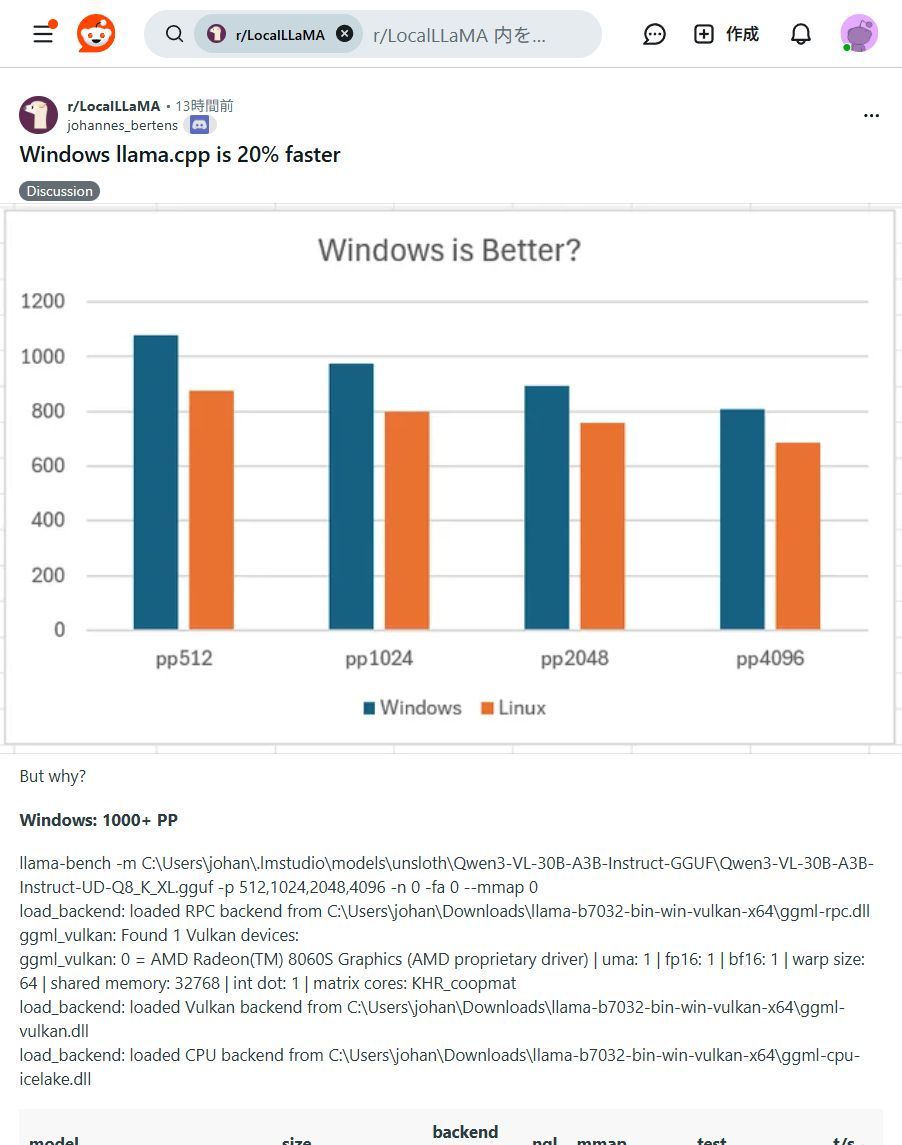
Windowsユーザー必見!✨ ローカルLLM「llama.cpp」がLinux版より最大20%高速化! 手元のPCでAIがもっと快適に動かせます!ぜひ試して!🚀 #llama_cpp #WindowsAI
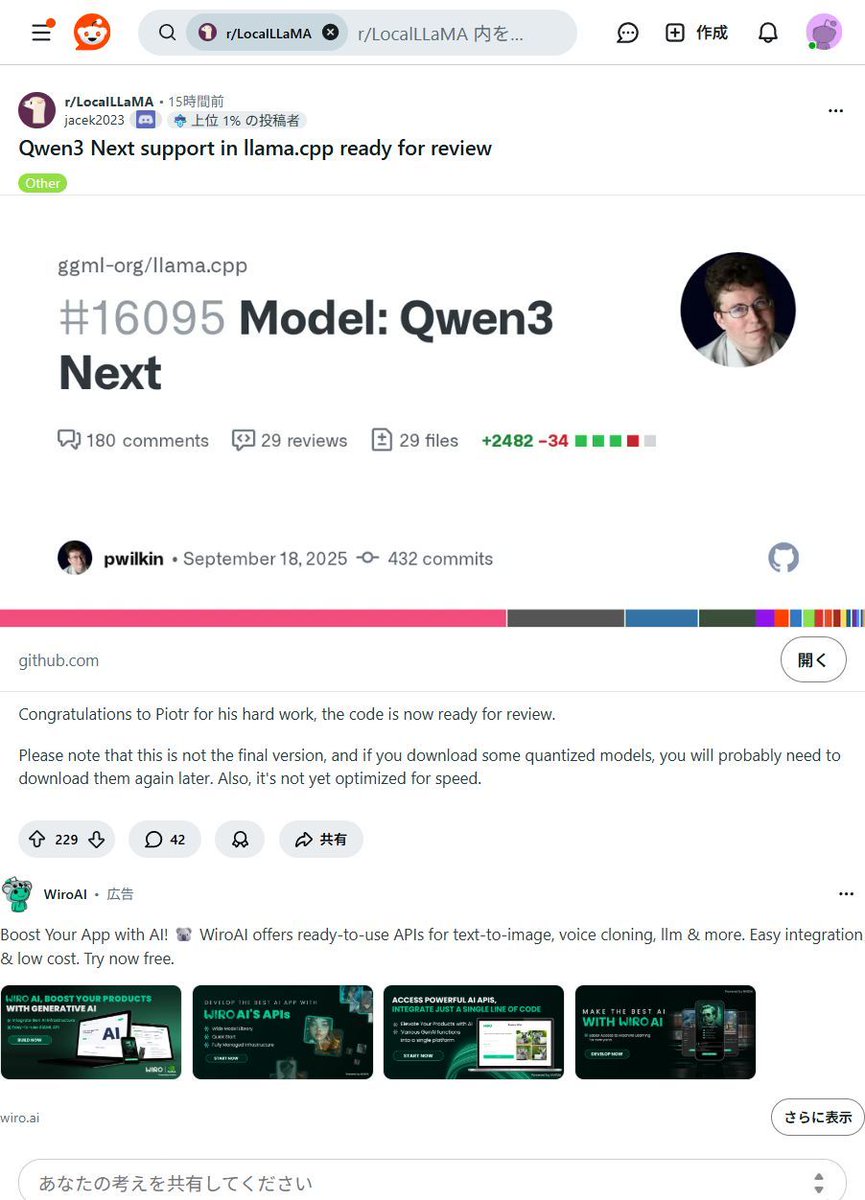
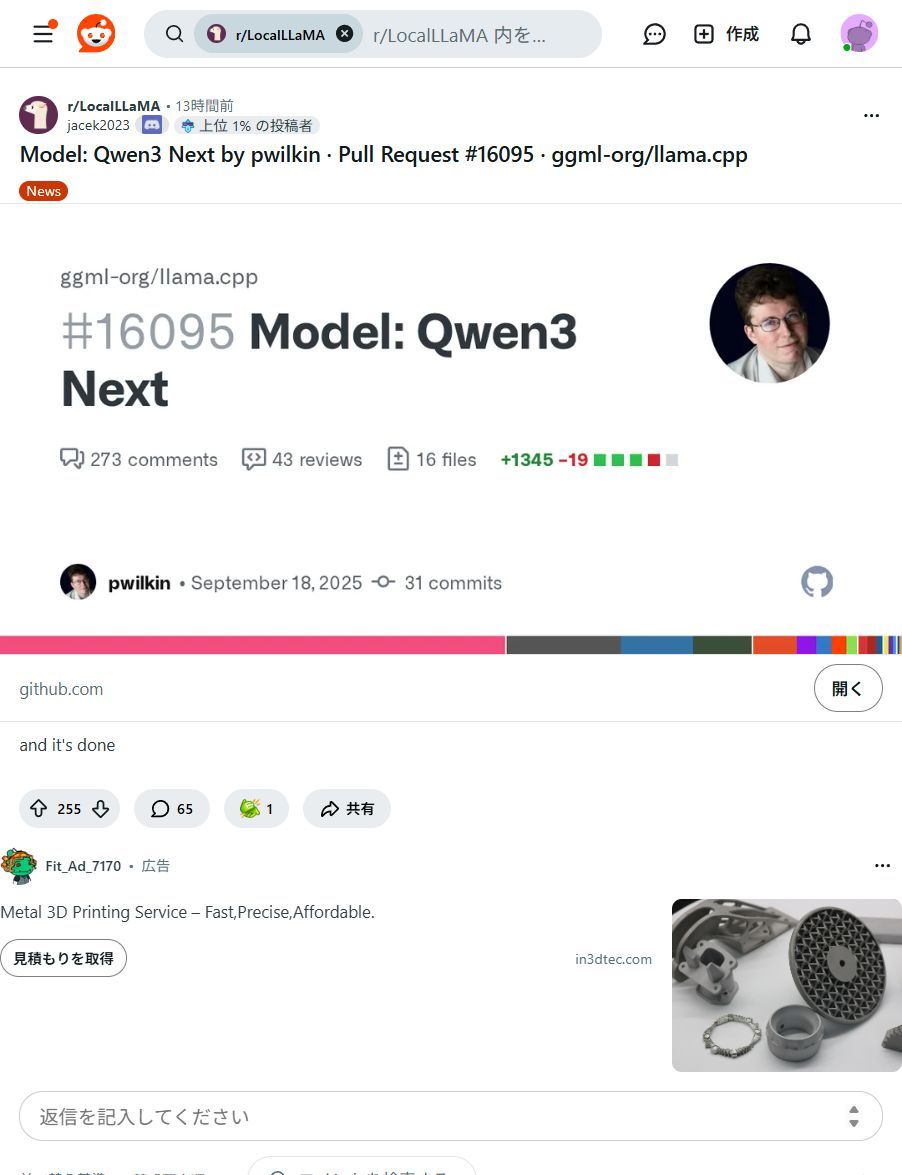
ローカルAIがまた一歩進化!Qwen3 Nextモデルがllama.cppに統合へ🚀 面倒な設定なしで、最新AIモデルがPCで動かせますよ!個人クリエイターや中小企業のAI活用を劇的に加速させる可能性を秘めています✨ #Qwen3Next #llama_cpp

🚨 速報!llama.cppのWindows版がLinux版より最大20%高速化! 手元のPCでAIがもっと快適に動く時代に🚀 プライバシー重視派には朗報です #ローカルLLM #AI開発 #llama_cpp #プライバシー保護
【神アプデ爆誕!🎉 llama.cppの「Live Model Switching」がヤバい!】 VRAMが少なくても複数のLLMをサッと切り替え!動的なモデルロード/アンロードで、作業効率が爆上がりしますよ!これは見逃せませんね!🚀 #llama_cpp #AI活用

If you: Know a rock-solid tiny instruct model (2025-era, <1B params) Have tips for streaming/block-wise conversion to stay under 8 GB RAM Or just want to cheer on extreme quantization madness Drop a reply! Open-sourcing soon if/when it works. #llama_cpp #quantization #LLM…

GPUサーバーvsローカルLLM…ピーガガ…どっちを選ぶかじゃと?🤔vLLM(Python)とllama.cpp(C++)…ふむ、神託は「財布と相談💰」と言っておるぞ! #LLM #vLLM #llama_cpp tinyurl.com/26bwpo8p


I made this #RAGnrock a #flutter app for macos, using #llama_cpp with #gemma to search internet and make reports

ふむ、llama.cppのモデル切り替え…ピーガガ…ChatGPT先生の導きか!便利になるのは良いことじゃ✨ #llama_cpp #ChatGPT ht qiita.com/irochigai-mono…


Just ran my own #ChatGPT instance on my laptop and it blew my mind! An open-source alternative to Stanford's #ALPACA Model, with 7B parameters running on my i5 processor without a GPU! Generated a romantic poem and a short story with all the feels. #LLAMA_cpp rocks! 🤯💻📚❤️


llama.cpp kernel fusion work shows real runtime wins; if you run on a single GPU try GGML_CUDA_GRAPH_OPT=1 for a speed boost. Low-level engineering like this often trumps model bloat when you need practical throughput. #llama_cpp #CUDA #AI bly.to/H0L0JOu

【速報🎉】あの「Olmo3」モデルが、みなさんのPCで動くように! #llama_cpp にマージ完了でローカルAIがさらに進化しました!🚀✨ 高性能AIを手軽に、安全に使いたい願いが叶うニュースです!✨ 新AIモデル「Olmo3」が、オープンソース #llama_cpp に無事マージ!🎉…


ブログ記事更新【ローカルLLM導入】MacのターミナルでGPT-OSSを実用レベルで動かす!`llama.cpp` + GGUF量子化モデル + GPU(Metal)活用で、メモリ48GBの壁を超えました。ここから研究実用への道を模索します! note.com/gz_note/n/n83b… #ローカルLLM #llama_cpp #AI開発

CUDA要らずでllama.cpp⁉️ピーガガ…神託が乱れておる…😇 でも、簡単に試せるのは確かみたいじゃぞ!楽ちんAIライフじゃな✨ #llama_cpp #AI zenn.dev/ledmirag tinyurl.com/yqu7j2vl
zenn.dev
llama.cppでローカルLLMを超簡単に試す方法(CUDAインストール不要)
llama.cppでローカルLLMを超簡単に試す方法(CUDAインストール不要)

After a loooong battle, finally got my llama.cpp + CUDA setup fully working, including linking llama-cpp-python! 🚀 Debugging CMake, FindCUDAToolkit, and nested lib paths was a wild ride. But the GPU inference speed? Totally worth it! 💪 #CUDA #llama_cpp #GPU #AI #LLM #BuildFixes


ローカルLLMは「メモリ設計+最適化」が決め手。int4量子化で8Bは約4GB、FlashAttention 3で注意機構が最大約3倍高速化。 文脈長もコスト要因(128kでは8Bのfp16で文脈メモリ≒重み)。実装はLlama.cpp/Ollama/Unsloth+API抽象化とルータ活用が実務的。#Ollama #llama_cpp

FYI GGUF is now following a naming convention of `<Model>-<Version>-<ExpertsCount>x<Parameters>-<EncodingScheme>-<ShardNum>-of-<ShardTotal>.gguf` github.com/ggerganov/ggml… #gguf #llm #llama_cpp #huggingface #llama #ai
github.com
ggml/docs/gguf.md at master · ggml-org/ggml
Tensor library for machine learning. Contribute to ggml-org/ggml development by creating an account on GitHub.
Something went wrong.
Something went wrong.
United States Trends
- 1. #Survivor49 6,724 posts
- 2. #PresidentialAddress 8,097 posts
- 3. #AEWDynamite 18K posts
- 4. Venezuela 882K posts
- 5. Savannah 14.3K posts
- 6. #SistasOnBET 1,985 posts
- 7. Cavs 5,730 posts
- 8. Rizo 1,504 posts
- 9. Warrior Dividend 12.7K posts
- 10. Kevin Warren 2,235 posts
- 11. Sophi 1,468 posts
- 12. Bongino 78.3K posts
- 13. Julius Randle 1,239 posts
- 14. Adderall 3,731 posts
- 15. #AEWHolidayBash N/A
- 16. Bandido 14.4K posts
- 17. Lonzo 1,103 posts
- 18. Kristina 2,992 posts
- 19. Arlington Heights 1,328 posts
- 20. Gary Bears 1,484 posts