

I've written a companion to this record talking about various tricks used in Modded NanoGPT's implementation of Muon. Do check it out! varunneal.github.io/essays/muon

@varunneal has set a new NanoGPT Speedrun WR of 132s with a batch size schedule, achieving an absurd peak of 30 steps/s! github.com/KellerJordan/m…. Read more on his improvements at varunneal.github.io/essays/muon, which include Cautious Weight Decay (@Tim38463182 et al) and Normuon tuning.


Really excited about our new paper which derives compute-optimal hyperparameter scaling for matrix-preconditioned optimizers. Muon is _particularly_ effective if we scale its hyperparameters properly, with significant gains over Adam in training LLMs!

Optimizers are only as good as our ability to predict good hyperparameters for them when used at scale. With robust hyperparameter transfer, we find Muon and Shampoo consistently beat AdamW by 1.4x and 1.3x in compute for training language models up to 1.4B parameters. 1/n
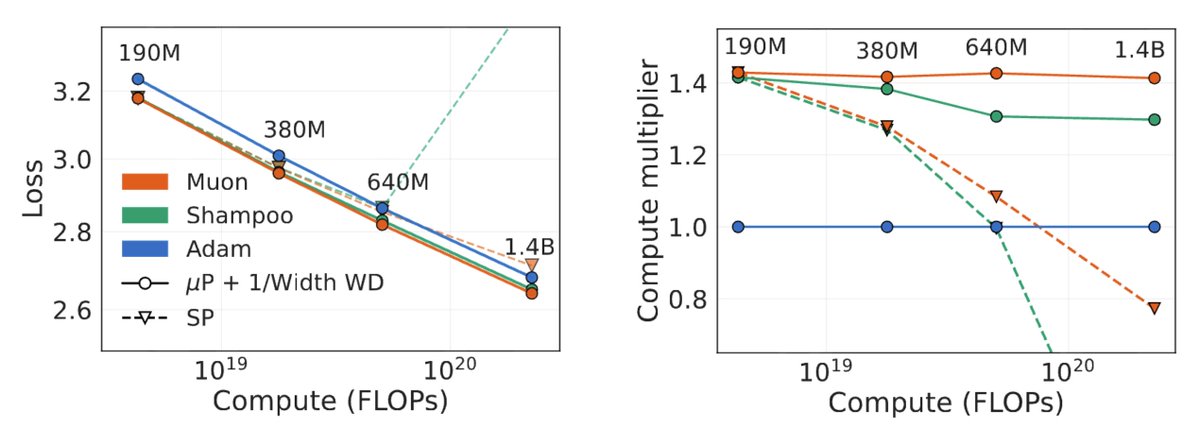
Optimizers are only as good as our ability to predict good hyperparameters for them when used at scale. With robust hyperparameter transfer, we find Muon and Shampoo consistently beat AdamW by 1.4x and 1.3x in compute for training language models up to 1.4B parameters. 1/n

Putnam, the world's hardest college-level math test, ended yesterday 4p PT. Noon today, AxiomProver solved 9/12 problems in Lean autonomously (3:58p PT yesterday, it was 8/12). Our score would've been #1 of ~4000 participants last year and Putnam Fellow (top 5) in recent years

This is incredible performance!

Putnam, the world's hardest undergrad math contest, ended 4pm PT yesterday. By 3:58pm, AxiomProver @axiommathai autonomously solved 8/12 of Putnam2025 in Lean, a 100% verifiable language. Last year, our score would've been #4 of ~4000 and a Putnam Fellow (top 10 in recent yrs)

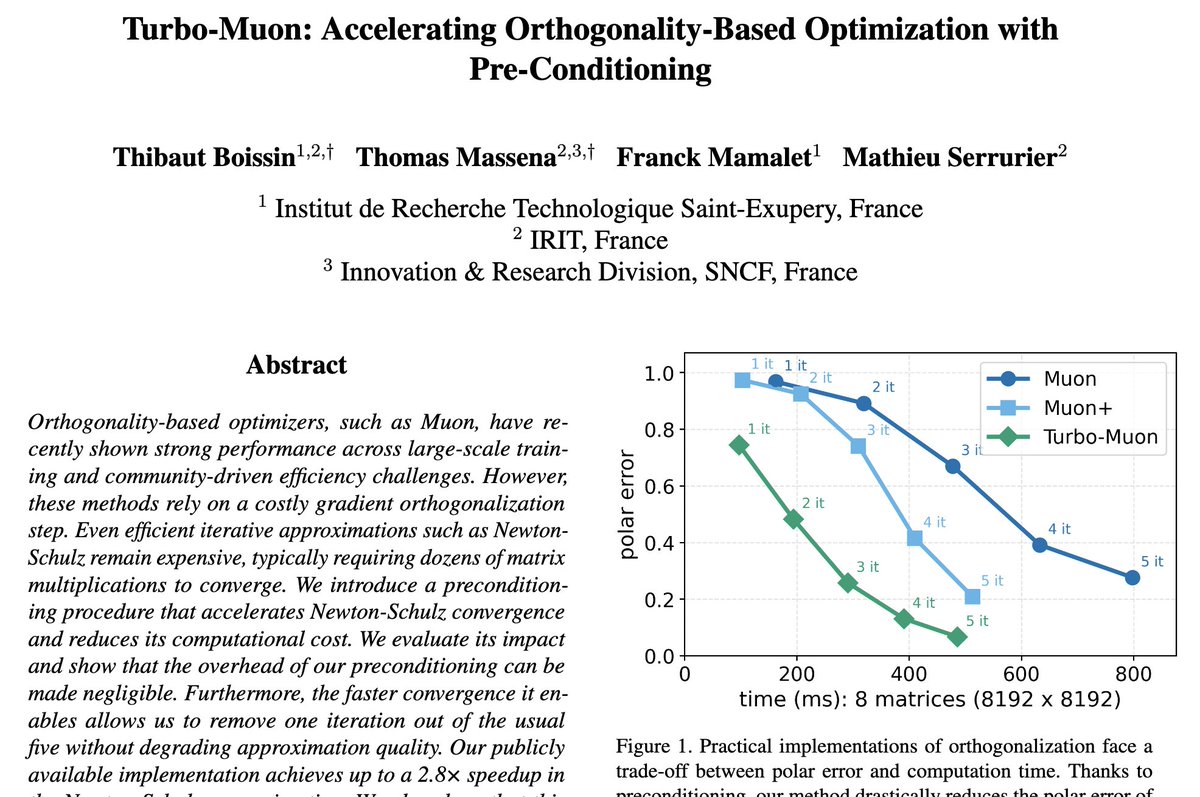
Interesting new variation of Muon called Turbo-Muon by @ThibautBoissin. It uses "almost orthogonal preconditioning" before Newton-Schulz -> reduces number of NS iterations needed to orthogonalize by 1 -> savings in per-iteration complexity. arxiv.org/abs/2512.04632


For anyone interested in understanding orthogonalization/spectral based methods here’s the slides from our #neurips25 oral that I tried to make more broadly about the topic.


Opus 4.5 is too good to be true. I think we've reached the "more than good enough" level; everything beyond this point may even be too much.

what the actual fuck how are people not talking about the fact that they found bio-essential sugars on an asteroid

🤔

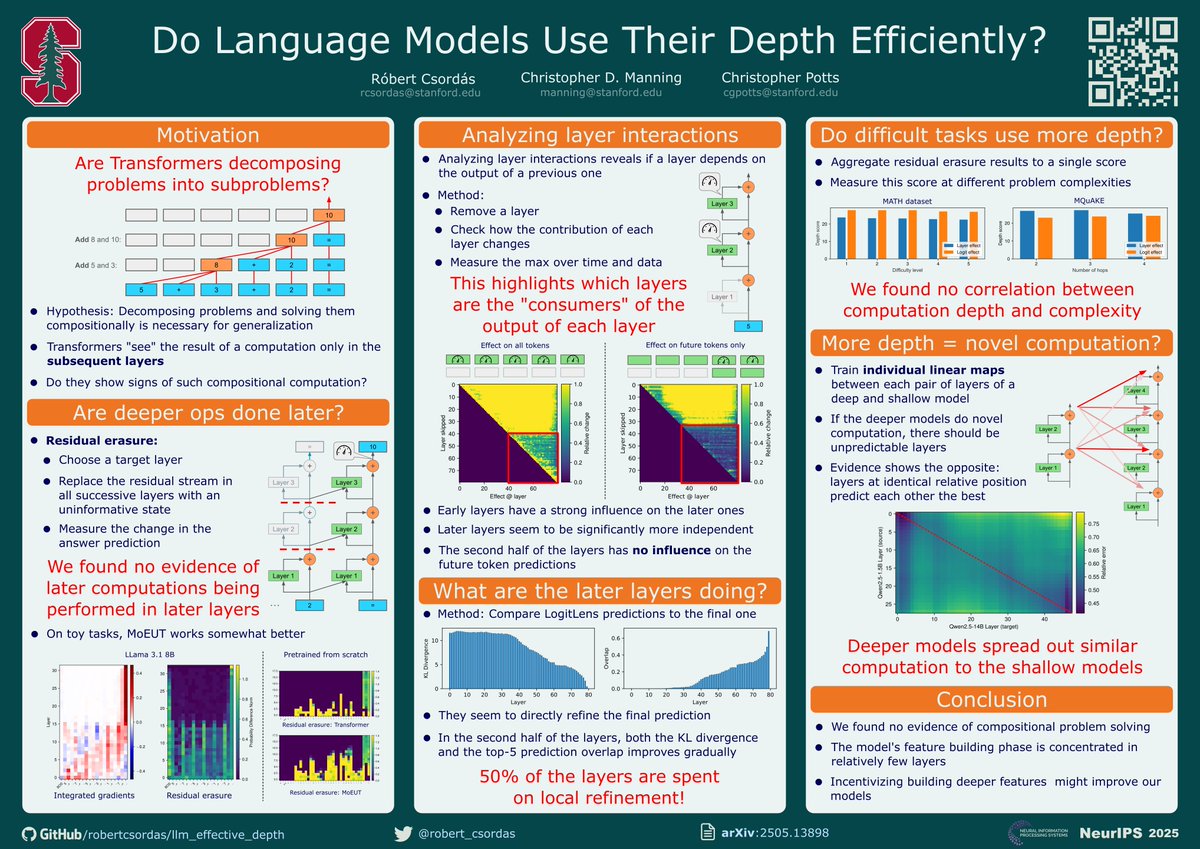
Attending @NeurIPSConf? Stop by our poster "Do Language Models Use Their Depth Efficiently?" with @chrmanning and @ChrisGPotts today at poster #4011 in Exhibit Hall C, D, E from 4:30pm.

GPT-5 generated the key insight for a paper accepted to Physics Letters B, a serious and reputable peer-reviewed journal.

This is the key step in which GPT5 proposes the main idea of the paper, completely de novo:


We need a talent tracker for all DeepSeek staff the rest aren't fodder whatsoever, there's only so many people that China sends to the IOI

Yi Qian= IOI Gold Medal and ICPC Gold Medal. Yuxiang Luo= IOI Gold Medal and ICPC Gold Medal Yuyang Zhou= IOI Gold Medal and ICPC Gold Medal Zuofan Wu= IOI Gold Medal Zhizhen Ren= IOI Gold Medal Xiangwen Wang= ICPC Gold Medal and 3401 Rating Codeforces. 👑
My message to labs is simple: Please multiply your reward function by some multiplicative factor of the form 10/log(total used token count) and subtract an additive factor of the form 10/log(number of reasoning tokens used after the correct answer is first mentioned in CoT).

New paper studies when spectral gradient methods (e.g., Muon) help in deep learning: 1. We identify a pervasive form of ill-conditioning in DL: post-activations matrices are low-stable rank. 2. We then explain why spectral methods can perform well despite this. Long thread


Couldn’t resist

We just tested Aleph prover on this version of Erdos #124 problem and were able to prove it in less that 2.5 hours and under $200 in cost: gist.github.com/winger/a2c27e4… x.com/vladtenev/stat…


DeepSeek V3.2 finally corrected the advantage calculation (in red). But they still keep the biased length norm term (in blue), which can lead to unhealthy response length behavior as we showed in arxiv.org/pdf/2503.20783. Check also tinker-docs.thinkingmachines.ai/losses to see how TML…


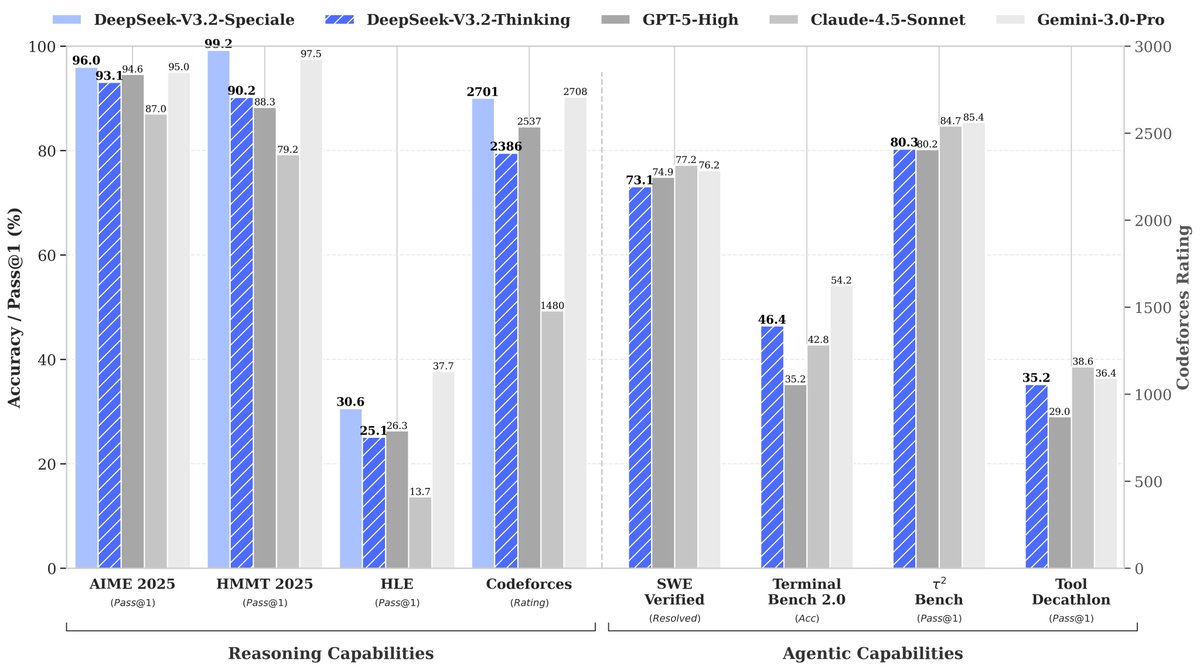
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…
no merging silliness. It is just a DSM-V2 plus everything else



NEW DEEPSEEK MODEL RELEASE 🚨 Two models: v3.2 - GPT-5 level performance v3.2 speciale - Gemini-3.0-Pro level performance, gold medal level for IMO, CMO, ICPC World Finals & IOI 2025 GRPO with modifications: - unbiased KL estimate - off-policy sequence masking - keep MoE…
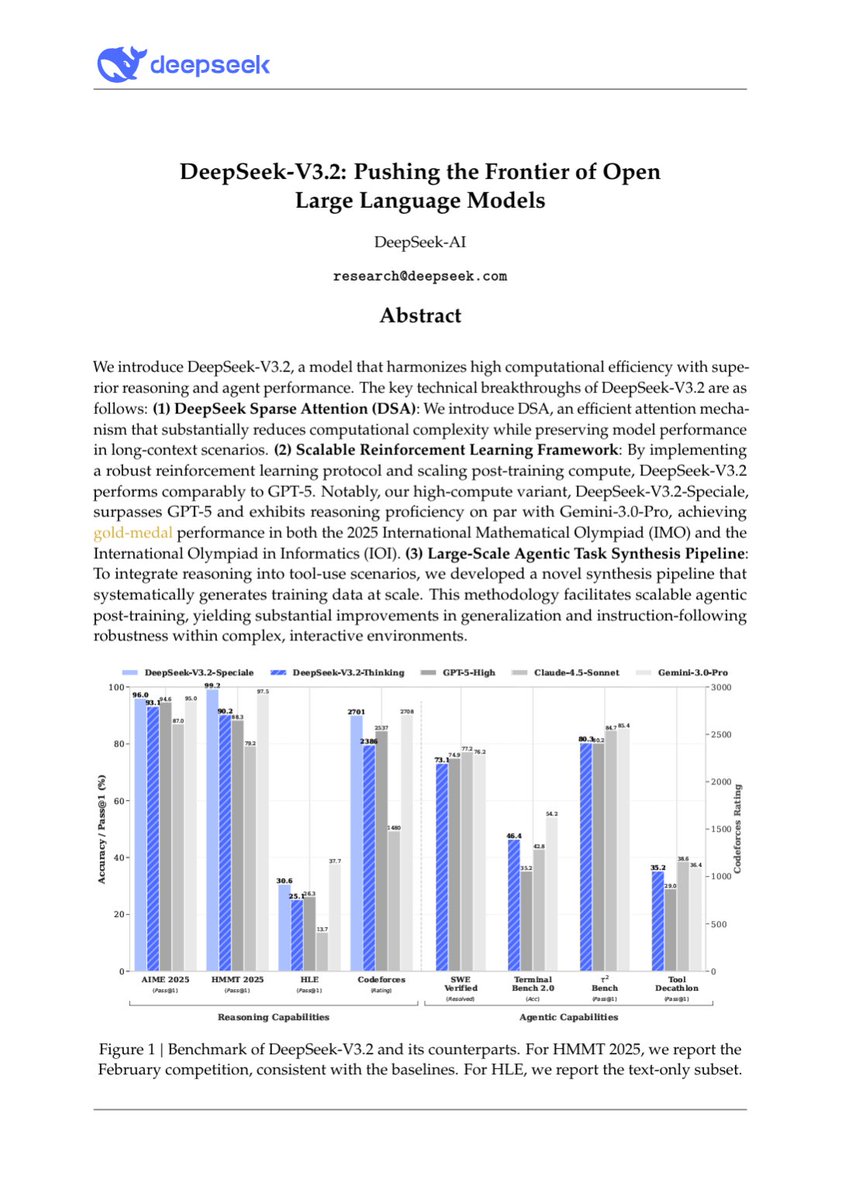
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…

The theorem statement details always matter a lot, and the ruling on this is that it solved a version of the problem but there is a harder version of the problem that is still open. It's very exciting still though




























































































United States 趨勢
- 1. FINALLY DID IT 564K posts
- 2. The BONK 104K posts
- 3. Good Tuesday 30.8K posts
- 4. $FULC 10.4K posts
- 5. US Leading Investment Team 6,825 posts
- 6. #Nifty 11.7K posts
- 7. Jalen 78.4K posts
- 8. Eagles 121K posts
- 9. Judah 3,984 posts
- 10. #tuesdayvibe 1,652 posts
- 11. Chargers 88.2K posts
- 12. Chainers 1,811 posts
- 13. LINGLING BA HAUS64 455K posts
- 14. #Haus64xLingMOME 450K posts
- 15. Piers 89.2K posts
- 16. #QG494 N/A
- 17. Herbert 34.4K posts
- 18. Oslo 74.3K posts
- 19. Fuentes 123K posts
- 20. Jasmine Crockett 83.6K posts
Something went wrong.
Something went wrong.