
Join us at the vLLM Takeover at Ray Summit 2025. we’ll be on stage Nov 5 in San Francisco. 🚀 #vLLM #RaySummit2025

🔥 Following our big announcement — here’s the full vLLM takeover at Ray Summit 2025! 📍 San Francisco • Nov 3–5 • Hosted by @anyscalecompute Get ready for deep dives into high-performance inference, unified backends, prefix caching, MoE serving, and large-scale…

The turnout at Malaysia @vllm_project Day was incredible! Huge thanks to vLLM, @lmcache, @EmbeddedLLM, @AMD, @RedHat, the Malaysian Government, YTL AI Labs, and our amazing WEKA team for making it possible and driving AI forward across ASEAN.



📢vLLM v0.12.0 is now available. For inference teams running vLLM at the center of their stack, this release refreshes the engine, extends long-context and speculative decoding capabilities, and moves us to a PyTorch 2.9.0 / CUDA 12.9 baseline for future work.

🚀 vLLM now offers an optimized inference recipe for DeepSeek-V3.2. ⚙️ Startup details Run vLLM with DeepSeek-specific components: --tokenizer-mode deepseek_v32 \ --tool-call-parser deepseek_v32 🧰 Usage tips Enable thinking mode in vLLM: –…


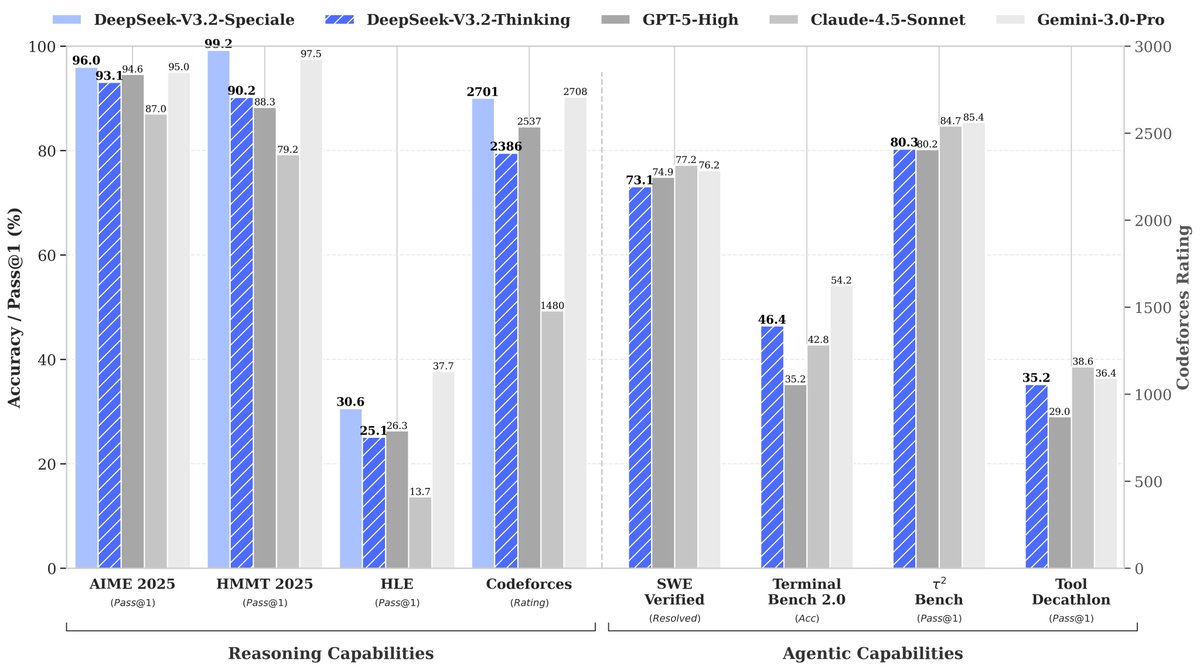
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…
🤝 Proud to share the first production-ready vLLM plugin for Gaudi, developed in close collaboration with the Intel team and fully aligned with upstream vLLM. 🔧 This release is validated and ready for deployment, with support for the latest vLLM version coming soon. 📘 The…

We’re taking CUDA debugging to the next level. 🚀 Building on our previous work with CUDA Core Dumps, we are releasing a new guide on tracing hanging and complicated kernels down to the source code. As kernels get more complex (deep inlining, async memory access), standard…

Have you ever felt you are developing cuda kernels and your tests often run into illegal memory access (IMA for short) and you have no idea how to debug? We have collaborated with the @nvidia team to investigate how cuda core dump can help, check out the blogpost to learn more!…
🎉 Congratulations to the Mistral team on launching the Mistral 3 family! We’re proud to share that @MistralAI, @NVIDIAAIDev, @RedHat_AI, and vLLM worked closely together to deliver full Day-0 support for the entire Mistral 3 lineup. This collaboration enabled: • NVFP4…

Introducing the Mistral 3 family of models: Frontier intelligence at all sizes. Apache 2.0. Details in 🧵


vLLM-Omni is an idea I’ve been thinking about for quite a while and we finally brought it to life! We’re really excited to collaborate with community to shape the future of this project, so feedbacks and contributions are very welcomed! Check it out!
More inference workloads now mix autoregressive and diffusion models in a single pipeline to process and generate multiple modalities - text, image, audio, and video. Today we’re releasing vLLM-Omni: an open-source framework that extends vLLM’s easy, fast, and cost-efficient…
More inference workloads now mix autoregressive and diffusion models in a single pipeline to process and generate multiple modalities - text, image, audio, and video. Today we’re releasing vLLM-Omni: an open-source framework that extends vLLM’s easy, fast, and cost-efficient…
🇲🇾 Malaysia vLLM Day is 5 days away. vLLM Malaysia Day — 2 Dec 2025 📍 ILHAM Tower, KL We are bringing the vLLM and @lmcache community together with @EmbeddedLLM, @AMD, @RedHat, @WekaIO to advance open, production-grade AI across ASEAN. The Lineup: 🚀 The State of vLLM &…


A practical guide to TP, DP, PP and EP on vLLM and @AMD GPU. @AIatAMD rocm.blogs.amd.com/software-tools…
Come work with us on vLLM!
🚀 vLLM Talent Pool is Open! As LLM adoption accelerates, vLLM has become the mainstream inference engine used across major cloud providers (AWS, Google Cloud, Azure, Alibaba Cloud, ByteDance, Tencent, Baidu…) and leading model labs (DeepSeek, Moonshot, Qwen…). To meet the…

🚀 vLLM Talent Pool is Open! As LLM adoption accelerates, vLLM has become the mainstream inference engine used across major cloud providers (AWS, Google Cloud, Azure, Alibaba Cloud, ByteDance, Tencent, Baidu…) and leading model labs (DeepSeek, Moonshot, Qwen…). To meet the…
Big night at the vLLM × Meta × AMD meetup in Palo Alto 💥 So fun hanging out IRL with fellow @vllm_project @woosuk_k, @simon_mo_ and the @AMD crew @AnushElangovan and @roaner. Bonus: heading home with a signed @RadeonPRO AI Pro R9700 to squeeze even more tokens/sec out of AMD…



Thanks to @github for spotlighting vLLM in the Octoverse 2025 report — one of the fastest-growing open-source AI projects this year. 🏆 Top OSS by contributors 🚀 Fastest-growing by contributors 🌱 Attracting the most first-time contributors Trusted by leading open model…

สวัสดีครับ Sawadekap, Bangkok! พร้อมจะโกลว์กันหรือยัง? ✨ vLLM Meetup — 21 Nov 2025 Hosted by @EmbeddedLLM, @AMD & @RedHat Members from the vLLM maintainer team will join us to share their latest insights and roadmap — straight from the source! We've also invited local Thai…

Awesome connecting with the @vllm_project community in person! @rogerw0108 @this_will_echo @hmellor_ @simon_mo_ @Rxday000 @chendi_xue @robertshaw21 @rockwell29139




vLLM team @vllm_project , reunited at Ray Summit! (Lowkey: can't wait to meet our magic @KaichaoYou and @darklight1337 in person!) Can't wait to meet our magic @KaichaoYou and @darklight1337 in person!

Happy to meet with @EmbeddedLLM people in person! Thanks for all the hardware supports in @vllm_project and @lmcache !

🔥Highly requested by the community, PaddleOCR-VL is now officially supported on vLLM! 🚀 Check out our recipe for this model to get started!👇docs.vllm.ai/projects/recip…
Amazing work by @RidgerZhu and the ByteDance Seed team — Scaling Latent Reasoning via Looped LMs introduces looped reasoning as a new scaling dimension. 🔥 The Ouro model is now runnable on vLLM (nightly version) — bringing efficient inference to this new paradigm of latent…

Thrilled to release new paper: “Scaling Latent Reasoning via Looped Language Models.” TLDR: We scale up loop language models to 2.6 billion parameters, and pretrained on > 7 trillion tokens. The resulting model is on par with SOTA language models of 2 to 3x size.

Wow Quantization-enhanced Reinforcement Learning using vLLM! Great job by @yukangchen_ 😃

We open-sourced QeRL — Quantization-enhanced Reinforcement Learning ! 🧠 4-bit quantized RL training 💪 Train a 32B LLM on a single H100 GPU ⚙️ 1.7× faster overall training 🎯 Accuracy on par with bfloat16-level accuracy 🔥 Supports NVFP4 quantization format Moreover, we show…































































































United States 趨勢
- 1. Texas Tech 25.6K posts
- 2. Messi 157K posts
- 3. Ty Simpson 1,664 posts
- 4. #SECChampionship 2,204 posts
- 5. Inter Miami 43.2K posts
- 6. #MLSCupFinal 1,266 posts
- 7. Harry Ford 1,164 posts
- 8. Slot 118K posts
- 9. Dawgs 7,918 posts
- 10. Big 12 2,791 posts
- 11. Gunner 5,700 posts
- 12. Busquets 12.1K posts
- 13. NDSU 1,241 posts
- 14. Liverpool 119K posts
- 15. Jordi Alba 7,296 posts
- 16. Ferrer 2,911 posts
- 17. Mariners 3,020 posts
- 18. Illinois State 7,870 posts
- 19. Ryan Williams N/A
- 20. #iubb 1,048 posts
Something went wrong.
Something went wrong.