

I crossed an interesting threshold yesterday, which I think many other mathematicians have been crossing recently as well. In the middle of trying to prove a result, I identified a statement that looked true and that would, if true, be useful to me. 1/3

you see that new attention variant? you’re going to be writing our custom CUDA kernel for it



Insane result and while the smaller training-inference gap makes sense, I cannot believe it has such a huge effect

FP16 can have a smaller training-inference gap compared to BFloat16, thus fits better for RL. Even the difference between RL algorithms vanishes once FP16 is adopted. Surprising!


between minimax ditching linear attention and kimi finding a variant that outperform full attention I’m completely confused

Kimi Linear Tech Report is dropped! 🚀 huggingface.co/moonshotai/Kim… Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi…


You see: - a new arch that is better and faster than full attention verified with Kimi-style solidness. I see: - Starting with inferior performance even on short contexts. Nothing works and nobody knows why. - Tweaking every possible hyper-parameter to grasp what is wrong. -…
Kimi Linear Tech Report is dropped! 🚀 huggingface.co/moonshotai/Kim… Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi…

7/12 You can clearly see the scaling in performance: With just 1 loop (T=1), the model performs poorly. At T=4 loops, its reasoning and math capabilities are much improved, reaching SOTA levels. More “thinking” directly translates to stronger capabilities.


> you are > MiniMax M2 pretrain lead > now everyone’s asking why you went full attention again > “aren’t you supposed to be the efficiency gang?” > efficient attention? yeah we tried > we trained small hybrids > looked good > matched full attention on paper > scaled up >…

MiniMax M2 Tech Blog 3: Why Did M2 End Up as a Full Attention Model? On behave of pre-training lead Haohai Sun. (zhihu.com/question/19653…) I. Introduction As the lead of MiniMax-M2 pretrain, I've been getting many queries from the community on "Why did you turn back the clock…

You can do TRM/HRM with reinforcement learning!

HRM-Agent: Using the Hierarchical Reasoning Model in Reinforcement Learning Paper: arxiv.org/abs/2510.22832 The Hierarchical Reasoning Model (HRM) has impressive reasoning abilities given its small size, but has only been applied to supervised, static, fully-observable problems.


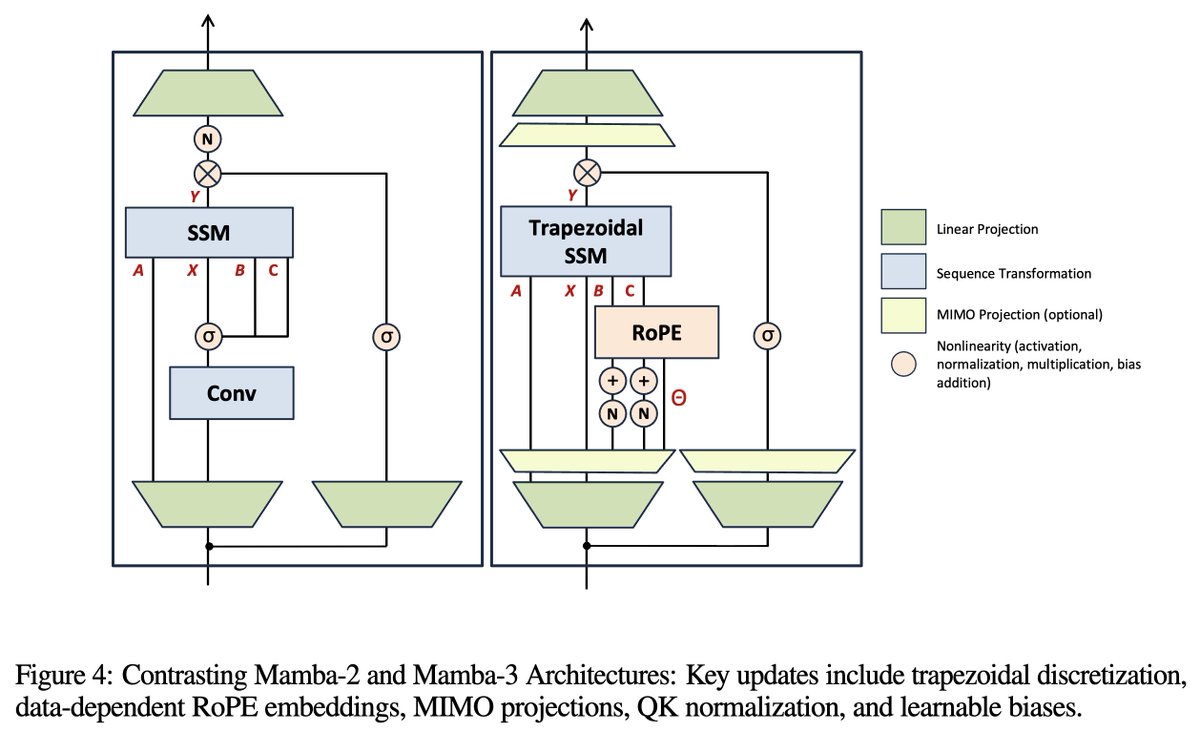
🎉 Our paper "Tensor Product Attention Is All You Need" has been accepted as NeurIPS 2025 Spotlight (Top 3%)! The Camera Ready version of TPA has been publicly available on the arXiv now: arxiv.org/abs/2501.06425 ⚡️TPA is stronger and faster than GQA and MLA, and is compatible…

🎉Our paper, "Tensor Product Attention Is All You Need," has been accepted for a spotlight presentation at the 2025 Conference on Neural Information Processing Systems (NeurIPS 2025)! See arxiv.org/abs/2501.06425 and github.com/tensorgi/TPA for details!
![yifan_zhang_'s tweet card. [NeurIPS 2025 Spotlight] TPA: Tensor ProducT ATTenTion Transformer (T6) (https://arxiv.org/abs/2501.06425) - tensorgi/TPA](https://pbs.twimg.com/card_img/1984121844698693632/R69jqlDD?format=jpg&name=orig)

I have a thing for empirical deep dive into learning dynamics like done in this paper. Sounds like muP mostly helps the early training, while wd affects the long term.

The Maximal Update Parameterization (µP) allows LR transfer from small to large models, saving costly tuning. But why is independent weight decay (IWD) essential for it to work? We find µP stabilizes early training (like an LR warmup), but IWD takes over in the long term! 🧵


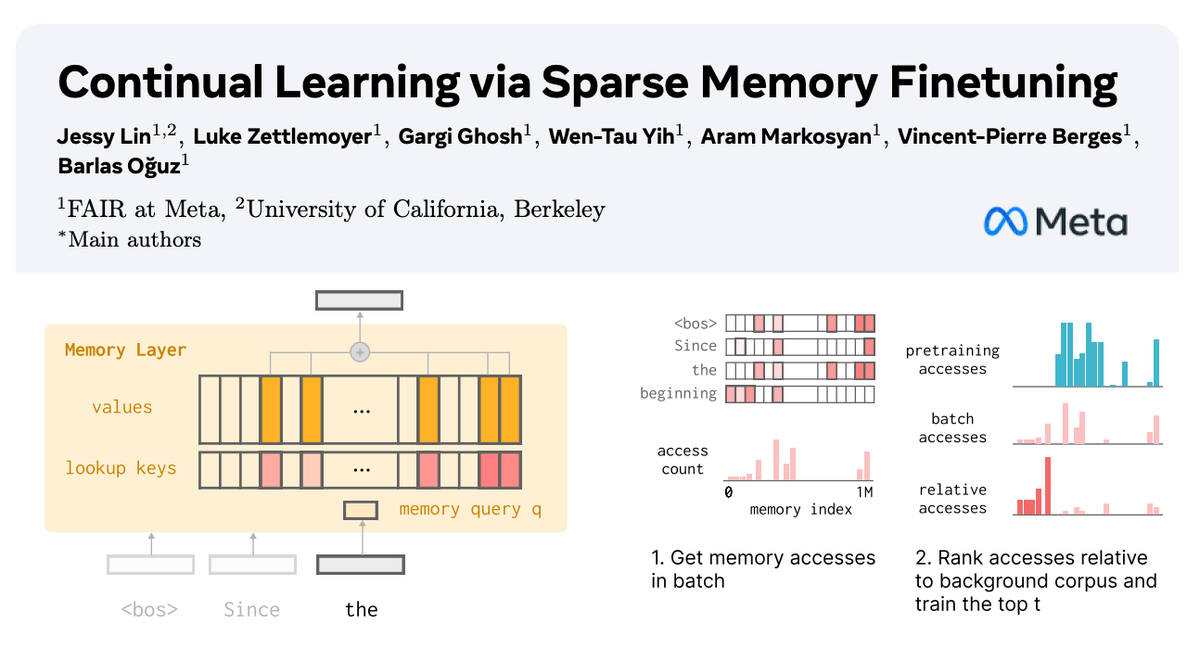
I think we're going to start seeing more continual learning techniques like this one that dynamically adapt which parameters are updated -- some really important ideas in here

🧠 How can we equip LLMs with memory that allows them to continually learn new things? In our new paper with @AIatMeta, we show how sparsely finetuning memory layers enables targeted updates for continual learning, w/ minimal interference with existing knowledge. While full…

well well well... happy perplexity death day

nice

diffusion transformers have come a long way, but most still lean on the old 2021 sd-vae for their latent space. that causes a few big issues: 1. outdated backbones make the architecture more complex than it needs to be. the sd-vae runs at around 450 gflops, while a simple ViT-B…


btw this discovery is by Mehtaab Sawhney (msawhney in the picture) mit.edu/~msawhney who has been doing lots of AWESOME works in combinatorics for many years now!
mit.edu
Mehtaab Sawhney — Clay Research Fellow & Assistant Professor at Columbia University
Mehtaab Sawhney — Clay Research Fellow and Assistant Professor at Columbia University. Research in combinatorics, probability, analytic number theory, and theoretical computer science.
gpt5-pro is superhuman at literature search: it just solved Erdos Problem #339 (listed as open in the official database erdosproblems.com/forum/thread/3…) by realizing that it had actually been solved 20 years ago h/t @MarkSellke for pointing this out to me!


Things that have happened since jan 2025: -Gemini 2.5 deepthink IMO got a gold medal on the IMO - unreleased openai model got a gold medal on the imo and ioi and a perfect score on the icpc - same unreleased openai model coded for 9 hours autonomously and got second place in the…

Matt Walsh is now "feeling the AGI." Meanwhile there's been ~zero change in real capabilities since we hit Midwit Wall (120 IQ) in January 2025. It's over. Send all these AI scams to zero prompto. 🚨🐻📉


🚀 NorMuon: Muon + Neuron-wise adaptive learning rates: +21.7% training efficiency vs Adam, +11.3% vs Muon on 1.1B pretrain. 🚀 Distributed Normuon: A highly efficient FSDP2 implementation. Paper 👉 arxiv.org/abs/2510.05491 #LLM #AI #DeepLearning #Optimizer



Ok I was unfair to @jm_alexia. had no time to read the TRM paper, I should have. It's a very good faith attempt to rescue the idea of enabling huge effective depth for a tiny model, without any shaky premises or unwarranted approximations of HRM. It may be a real, big finding.





TRM is one of the best papers I've read in the past years - it truly shows the unfiltered process of a researcher: 1) See awesome paper, get hyped about it 2) Read it - looks cool 3) Run it - doesn't work 4) Find glaring mistakes 5) Fix the issues x.com/jm_alexia/stat…
































































































United States Xu hướng
- 1. Dick Cheney 15.5K posts
- 2. Election Day 79.3K posts
- 3. Good Tuesday 24.7K posts
- 4. #tuesdayvibe 1,327 posts
- 5. GO VOTE 67.7K posts
- 6. Rolex 15.4K posts
- 7. George W. Bush 7,226 posts
- 8. #Election2025 2,088 posts
- 9. #WeTVAlwaysMore2026 1.41M posts
- 10. Hogg 6,842 posts
- 11. Halliburton 1,083 posts
- 12. iPads N/A
- 13. Jonathan Bailey 44.3K posts
- 14. Comey 93.4K posts
- 15. #AllsFair N/A
- 16. Nick Smith 19.5K posts
- 17. Nino 49K posts
- 18. Jake Paul 5,748 posts
- 19. #LakeShow 3,502 posts
- 20. Ben Shapiro 72.3K posts
Something went wrong.
Something went wrong.