
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI's GPT-5 model to evaluate the LLM's ability to reason through and find errors in complex codebases! Our evals found GPT-5 performed up to 190% better than other leading models!
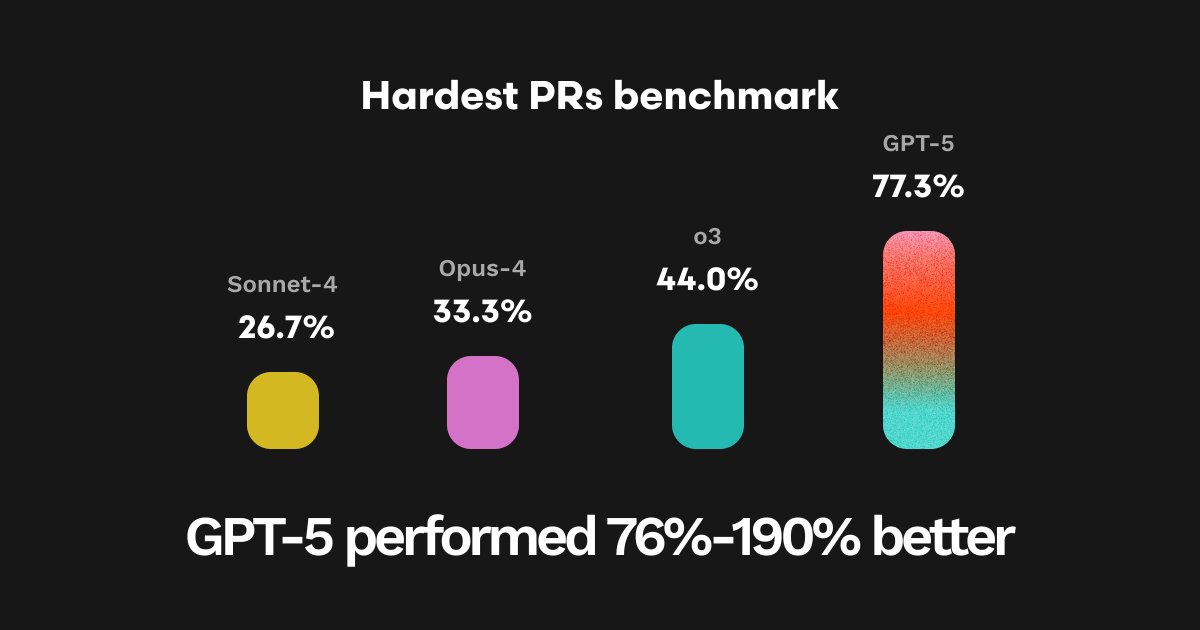

How did the comparison stand with opus 4.1 and grok 4? Those are the leading models from competitors and they should present in comparison.
We only tested GPT-5 against previous top performers on our tests and ultimately grok 4 didn’t perform up to the same standard so wasn’t used in this test!
United States Xu hướng
- 1. Elander 2,840 posts
- 2. Tosin 7,911 posts
- 3. Tony Vitello 11.3K posts
- 4. Danny White 2,390 posts
- 5. Ajax 64.9K posts
- 6. Caicedo 16.7K posts
- 7. $TSLA 40.4K posts
- 8. Ekitike 21K posts
- 9. Estevao 18.5K posts
- 10. East Wing 135K posts
- 11. Enzo 26.6K posts
- 12. #YesOnProp50 4,541 posts
- 13. Frank Anderson N/A
- 14. SNAP 644K posts
- 15. Frankfurt 40.8K posts
- 16. Hamburger Helper N/A
- 17. Isak 19.6K posts
- 18. Brahim 7,276 posts
- 19. Donte N/A
- 20. Surviving Mormonism N/A
Loading...
Something went wrong.
Something went wrong.