
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI's GPT-5 model to evaluate the LLM's ability to reason through and find errors in complex codebases! Our evals found GPT-5 performed up to 190% better than other leading models!
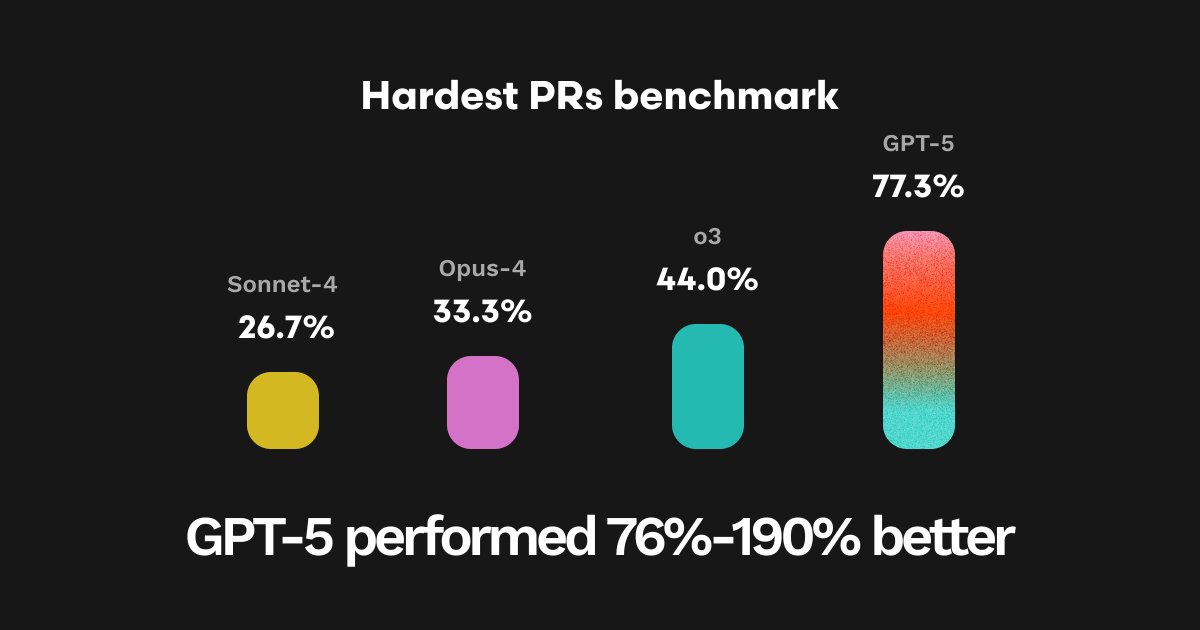

How did the comparison stand with opus 4.1 and grok 4? Those are the leading models from competitors and they should present in comparison.
We only tested GPT-5 against previous top performers on our tests and ultimately grok 4 didn’t perform up to the same standard so wasn’t used in this test!
United States Trends
- 1. #UFC321 112K posts
- 2. Gane 126K posts
- 3. Aspinall 113K posts
- 4. Jon Jones 10.4K posts
- 5. Ryan Williams N/A
- 6. Liverpool 168K posts
- 7. Mizzou 4,840 posts
- 8. South Carolina 11.1K posts
- 9. Ty Simpson 1,486 posts
- 10. Mateer 5,894 posts
- 11. Matt Zollers N/A
- 12. Aaron Henry N/A
- 13. Iowa 16.2K posts
- 14. Kirby Moore N/A
- 15. June Lockhart 4,735 posts
- 16. Slot 110K posts
- 17. Pribula 1,156 posts
- 18. Arch 18.1K posts
- 19. Sark 4,322 posts
- 20. Brentford 71.6K posts
Loading...
Something went wrong.
Something went wrong.