
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI's GPT-5 model to evaluate the LLM's ability to reason through and find errors in complex codebases! Our evals found GPT-5 performed up to 190% better than other leading models!
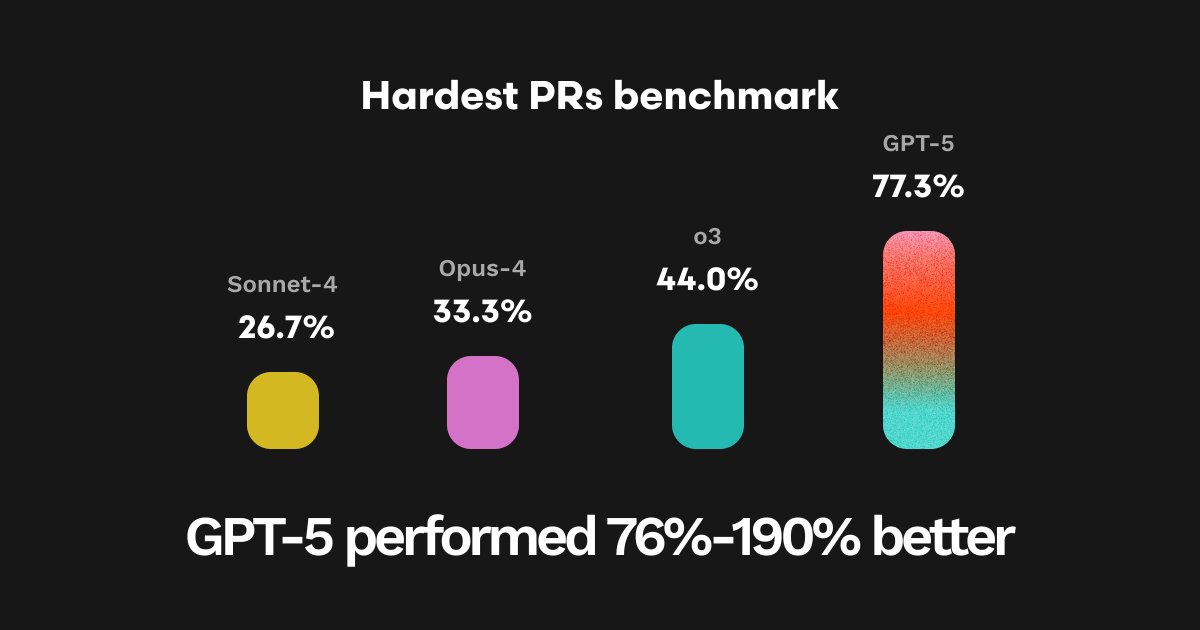

How did the comparison stand with opus 4.1 and grok 4? Those are the leading models from competitors and they should present in comparison.
We only tested GPT-5 against previous top performers on our tests and ultimately grok 4 didn’t perform up to the same standard so wasn’t used in this test!
United States 趋势
- 1. Good Monday 33.3K posts
- 2. #MondayMotivation 27.3K posts
- 3. Victory Monday N/A
- 4. Jamaica 63.8K posts
- 5. Category 5 16.3K posts
- 6. #MondayVibes 2,118 posts
- 7. Hurricane Melissa 39.4K posts
- 8. #BacktoLife 26.7K posts
- 9. Tomlin 13.5K posts
- 10. Cameroon 13.6K posts
- 11. Milei 581K posts
- 12. Hochul 22K posts
- 13. GameStop 56K posts
- 14. Austin Reaves 51.5K posts
- 15. Tanzania 58.9K posts
- 16. Talus Labs 17.9K posts
- 17. South China Sea 18.3K posts
- 18. #BreachLAN2 3,721 posts
- 19. Dolly 13K posts
- 20. Ron Paul N/A
Loading...
Something went wrong.
Something went wrong.