
Bunları beğenebilirsin








13/ A final tip: probably the most important thing to get great results out of Claude Code -- give Claude a way to verify its work. If Claude has that feedback loop, it will 2-3x the quality of the final result. Claude tests every single change I land to claude.ai/code…

I learned about agentic ai from the 'Agentic AI' mooc course agenticai-learning.org/f25 it completely reframed my understanding of where AI is heading. We are witnessing a massive paradigm shift: moving from Human Aligned Models to Environment Feedback Aligned Models.


Last month, Google dropped something interesting: five AI Agent papers released across five consecutive days, one per day, each digging into a different part of how agents should be built, evaluated, secured, and deployed. No big splash, just a steady rollout of more than 250…

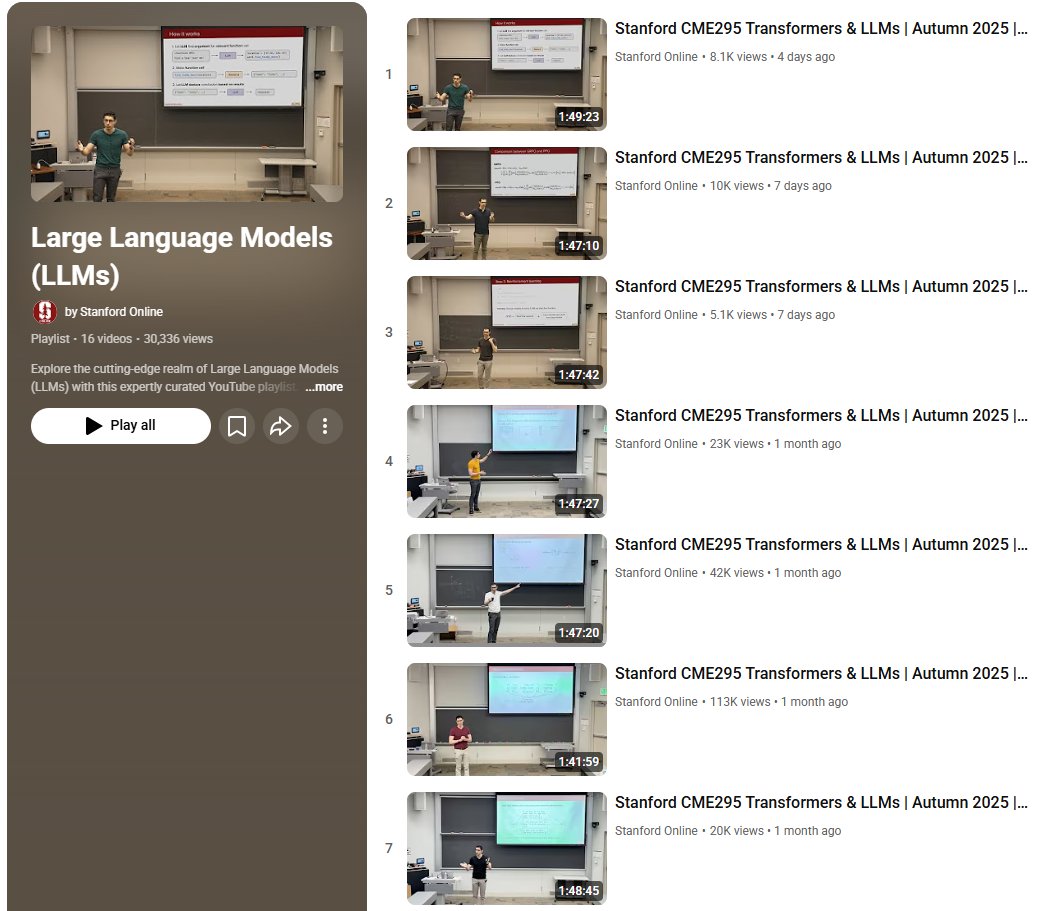
Make the most of your weekend. Don't sleep on this. Stanford's Autumn 2025 Transformers & LLMs course. 7 lectures. Free. While others scroll, you could understand how Flash Attention achieves 3x speedup, how LoRA cuts fine-tuning costs by 90%, and how MoE makes models…

最近我们团队跟 SGLang 社区给 slime 贡献了 KIMI K2 RL 的代码。之前我们 Multi-Agent 强化学习方案 MrlX 就是基于 slime 做的。我们特别喜欢 slime 的设计:rollout 代码跟训练引擎完全解耦,Infra同学在升级框架的时候,我们 DeepResearch Agent 的训练代码完全无感。欢迎大家尝试用 slime 对 KIMI…

Ant AQ-Team @AQ_MedAI @TheInclusionAI and SGLang RL Team @sgl_project just helped land Kimi-K2-Instruct RL on slime — fully wired up and running on 256× H20 141GB 🚀 Huge shout-out to @yngao016, @menlzy, @Yonah_x from AQ Team and @Ji_Li_233, @Yefei_RL from the SGLang RL Team for…


🚀 Hello, Kimi K2 Thinking! The Open-Source Thinking Agent Model is here. 🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%) 🔹 Executes up to 200 – 300 sequential tool calls without human interference 🔹 Excels in reasoning, agentic search, and coding 🔹 256K context window Built…


Training LLMs end to end is hard. Very excited to share our new blog (book?) that cover the full pipeline: pre-training, post-training and infra. 200+ pages of what worked, what didn’t, and how to make it run reliably huggingface.co/spaces/Hugging…




Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning Breaks down SFT dataset demonstrations into a sequence of actions, generate internal reasoning before each action, reward based on similarity of model's actions and expert actions. Experiments…


🚨 This might be the biggest leap in AI agents since ReAct. Researchers just dropped DeepAgent a reasoning model that can think, discover tools, and act completely on its own. No pre-scripted workflows. No fixed tool lists. Just pure autonomous reasoning. It introduces…


1/4 Following up on our launch of Tongyi DeepResearch: We're now releasing the full technical report! Dive deep into the technology and insights behind our 30B (A3B) open-source web agent that achieves SOTA performance: 32.9 on Humanity's Last Exam, 43.4 on BrowseComp, and 46.7…


Introducing Multi-Agent Evolve 🧠 A new paradigm beyond RLHF and RLVR: More compute → closer to AGI No need for expensive data or handcrafted rewards We show that an LLM can self-evolve — improving itself through co-evolution among roles (Proposer, Solver, Judge) via RL — all…




And if anyone wants to contribute an additional dataset the instructions are available here: github.com/neulab/agent-d…
github.com
agent-data-protocol/CONTRIBUTING.md at main · neulab/agent-data-protocol
Contribute to neulab/agent-data-protocol development by creating an account on GitHub.

在开发 Agent 应用,当想让它能通过实际运行数据不断学习优化,但是该功能实现起来颇为复杂。 微软技术团队,最近开源了一个叫 “Agent Lightning” 项目,将这个技术门槛大幅降低,轻松为 Agent 加上自我优化能力。…


This survey systematizes RL methods for agentic AI, covering data, training, evaluation, and practical guidance. Read the full paper on the Hugging Face Hub: huggingface.co/papers/2509.06… Explore the code & resources: github.com/wenjunli-0/dee…


Agentic Context Engineering Great paper on agentic context engineering. The recipe: Treat your system prompts and agent memory as a living playbook. Log trajectories, reflect to extract actionable bullets (strategies, tool schemas, failure modes), then merge as append-only…


Our new Gemini 2.5 Computer Use model can navigate browsers just like you do. 🌐 It builds on Gemini’s visual understanding and reasoning capabilities to power agents that can click, scroll and type for you online - setting a new standard on multiple benchmarks, with faster…

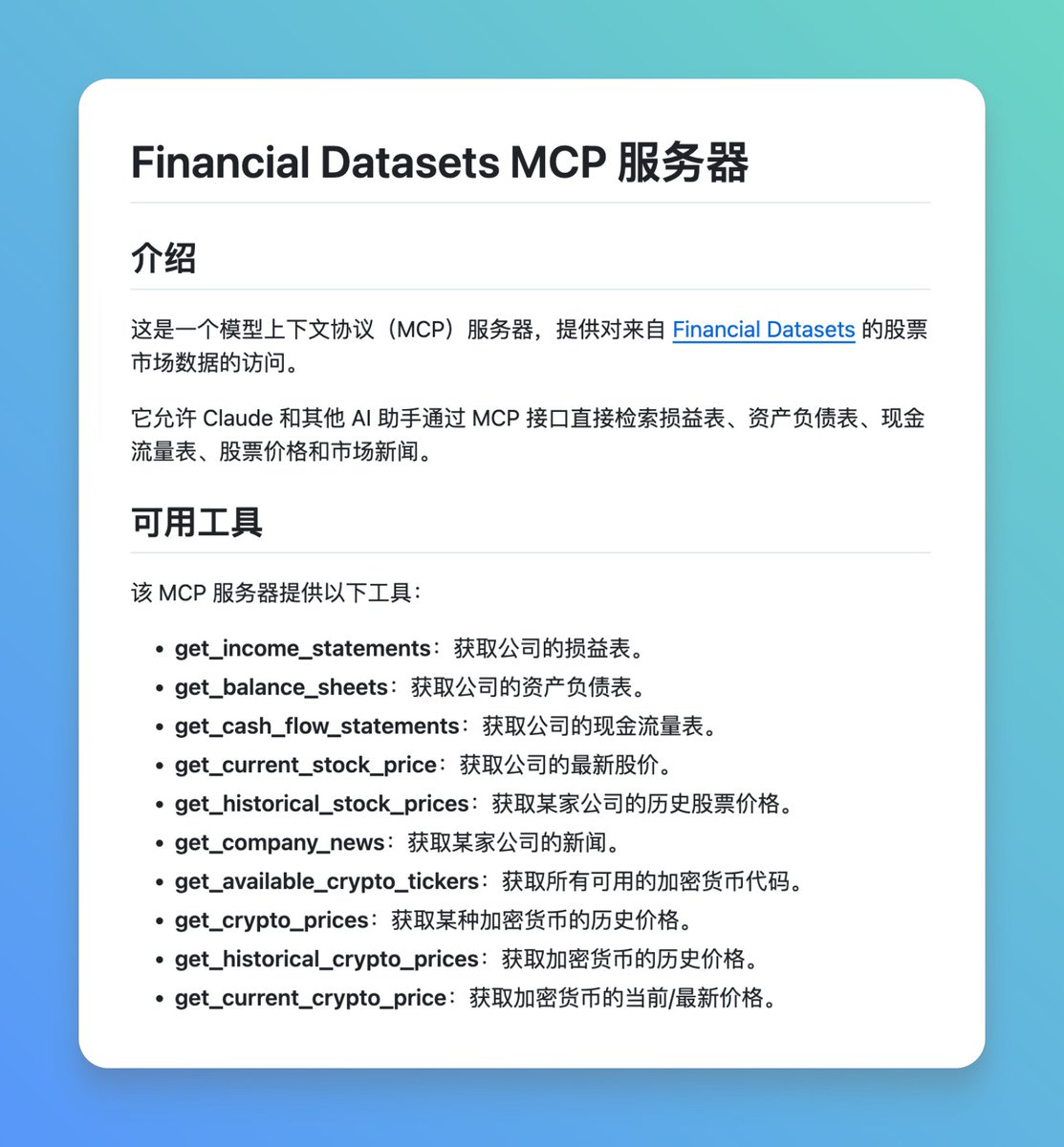
在做投资分析或市场研究,我们需要从不同网站收集股价、财报、新闻等信息,来回查找颇为耗时。 现在只需要给 AI 助手装一个 Financial Datasets MCP 服务器,即可在同一对话中直接获取相关实时数据。 比如查询公司的损益表、资产负债表、现金流量表,还能获取股票价格、市场新闻等等信息。…

我的一人公司,再添一名数字员工——B站+YouTube的运营专员(Claude Code+Chrome Devtools MCP) 事情这样,为你提升视频的互动率,我比较常用的一个内容运营策略是在做完视频后,再做一份图文教程或视频相关的素材,让观众留言特点关键词获取。…


























































































United States Trendler
- 1. Pro Bowl N/A
- 2. Shedeur Sanders N/A
- 3. Homan N/A
- 4. Tyler Huntley N/A
- 5. #OlandriaxRahulMishra N/A
- 6. Highguard N/A
- 7. Kanye N/A
- 8. Tyra N/A
- 9. Harrison Bader N/A
- 10. Soucy N/A
- 11. $SLV N/A
- 12. Roval N/A
- 13. Ran Gvili N/A
- 14. Medic N/A
- 15. Paul Newman N/A
- 16. #MaduroCiliaHeroes N/A
- 17. #MondayMotivation N/A
- 18. Signal N/A
- 19. Michael Burry N/A
- 20. Amex N/A







Something went wrong.
Something went wrong.