

Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…


When should an LLM learn to reason? 🤔 Early in pretraining or late in fine-tuning? Our new work, "Front-Loading Reasoning", challenges the "save it for later" approach. We show that injecting reasoning data into pretraining is critical for building models that reach the…


New paper 📜: Tiny Recursion Model (TRM) is a recursive reasoning approach with a tiny 7M parameters neural network that obtains 45% on ARC-AGI-1 and 8% on ARC-AGI-2, beating most LLMs. Blog: alexiajm.github.io/2025/09/29/tin… Code: github.com/SamsungSAILMon… Paper: arxiv.org/abs/2510.04871

My brain broke when I read this paper. A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2. It's called Tiny Recursive Model (TRM) from Samsung. How can a model 10,000x smaller be smarter? Here's how…


A beautiful paper from MIT+Harvard+ @GoogleDeepMind 👏 Explains why Transformers miss multi digit multiplication and shows a simple bias that fixes it. The researchers trained two small Transformer models on 4-digit-by-4-digit multiplication. One used a special training method…


Very interesting result! Though perhaps not too surprising if you recall that RL-tuned models often show much smaller feature shifts than SFT (see e.g. Xiang’s post below). When the model doesn’t have to move very far, LoRA—or even something lighter—can already do the job. As…

LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…


Meta AI’s new paper shows that strong chain-of-thought reasoning can emerge in models under 1 billion parameters if you feed them the right data. Key takeaways 🔹Smaller, smarter. MobileLLM-R1 (140 M – 950 M params) beats or matches prior open-source peers on reasoning suites…


LoRA in reinforcement learning (RL) can match full-finetuning performance when done right! 💡 A new @thinkymachines post shows how using 10x larger learning rates, applying LoRA on all layers & more, LoRA at rank=1 even works. We're excited to have collaborated on this blog!
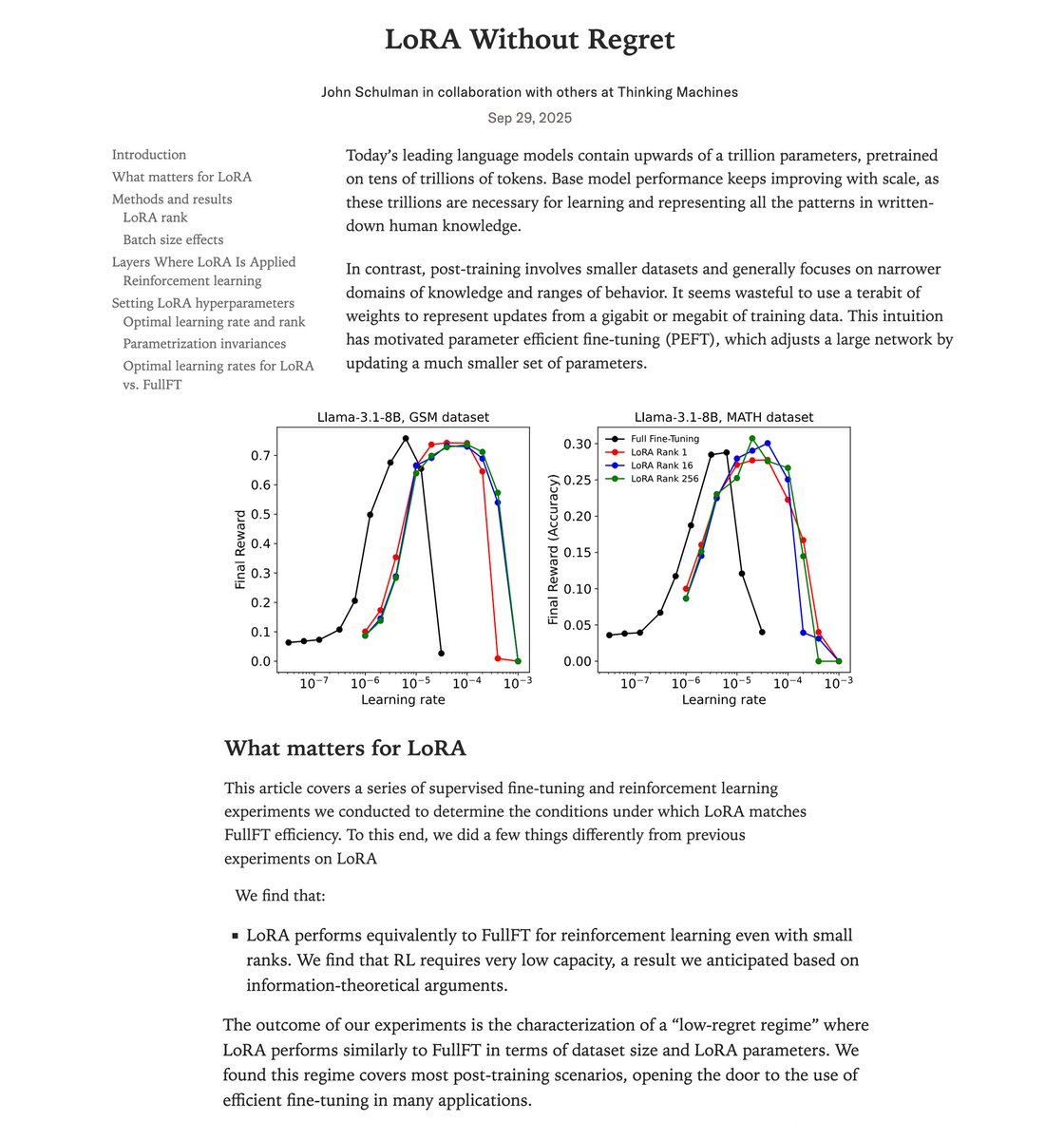
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…

Great work showing prompt synthesis as a new scaling axis for reasoning. Good training data is scarce. This work showcases a framework that might make it possible to construct high-quality training problems for reasoning-focused LLMs. Technical details below:


Yet more evidence that a pretty major shift is happening, this time by Scott Aaronson scottaaronson.blog/?p=9183&fbclid…


I have a new blog post about the so-called “tokenizer-free” approach to language modeling and why it’s not tokenizer-free at all. I also talk about why people hate tokenizers so much!


Damn, very interesting paper. after rapid loss reduction, we see deceleration and follow "scaling law": this is because at these steps, gradients start to conflict each other. Updates are 'fightining for modal capacity' in some sense, and larger the model less fighting there…


Correct! Just as a reminder: this is what a Transformer found after looking at 10M solar systems
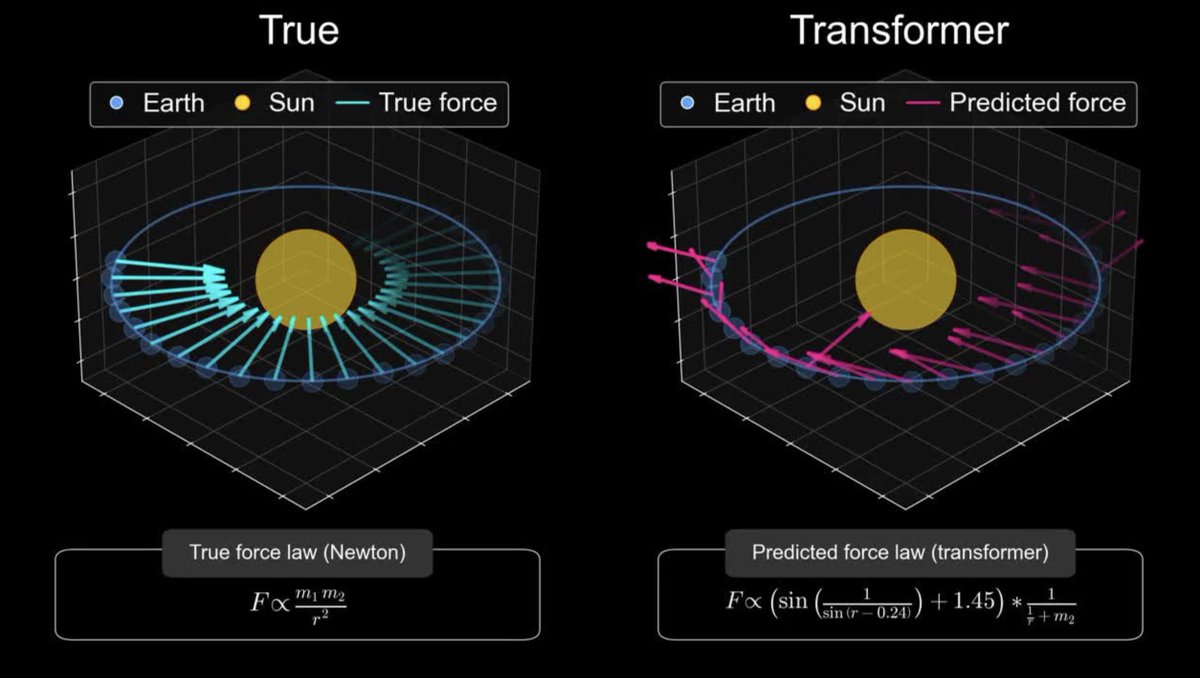

A student who truly understands F=ma can solve more novel problems than a Transformer that has memorized every physics textbook ever written.


This is interesting as a first large diffusion-based LLM. Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to…

We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the frontier of intelligence and speed with parallel, coarse-to-fine text generation.

Why do we treat train and test times so differently? Why is one “training” and the other “in-context learning”? Just take a few gradients during test-time — a simple way to increase test time compute — and get a SoTA in ARC public validation set 61%=avg. human score! @arcprize


Diffusion LLMs are promising ways to overcome the limitations of autoregressive LLMs. Less error propagation, easier to control, and faster to sample! But how do Diffusion LLMs actually work? 🤔 Let's explore some ideas on this fascinating topic! youtu.be/8BTOoc0yDVA

Self-Questioning Language Models: LLMs that learn to generate their own questions and answers via asymmetric self-play RL. There is no external training data – the only input is a single prompt specifying the topic.


Current AI benchmarks test textbook knowledge, but scientific discovery is iterative and creative, and that's where evaluation gets messy. @chenru_duan (MIT→Microsoft→startup founder) and I discuss his journey and the open source project Scientific Discovery Evaluation…


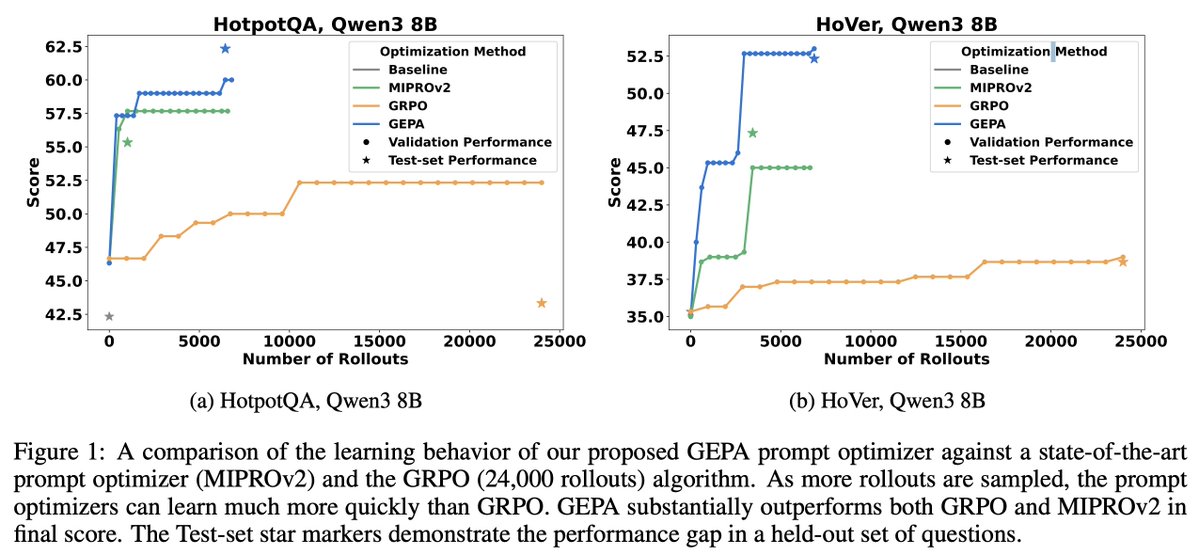
How does prompt optimization compare to RL algos like GRPO? GRPO needs 1000s of rollouts, but humans can learn from a few trials—by reflecting on what worked & what didn't. Meet GEPA: a reflective prompt optimizer that can outperform GRPO by up to 20% with 35x fewer rollouts!🧵





































































United States 트렌드
- 1. Bears 88.1K posts
- 2. Jake Moody 13.3K posts
- 3. Snell 23.5K posts
- 4. Falcons 50.7K posts
- 5. Caleb 48.4K posts
- 6. Bills 140K posts
- 7. Josh Allen 26.1K posts
- 8. #BearDown 2,328 posts
- 9. Jayden 22.6K posts
- 10. Swift 289K posts
- 11. phil 168K posts
- 12. Ben Johnson 4,310 posts
- 13. #Dodgers 15K posts
- 14. Turang 4,247 posts
- 15. Joji 27.1K posts
- 16. Troy Aikman 6,273 posts
- 17. Bijan 32.3K posts
- 18. Roki 6,052 posts
- 19. #RaiseHail 8,429 posts
- 20. Brewers 47.9K posts
Something went wrong.
Something went wrong.