




Sebastien Bubeck just cleared the air and honestly, it makes GPT-5’s achievement even more astonishing. No, GPT-5 didn’t magically solve a new Erdős problem. What it did was arguably harder to appreciate: it rediscovered a long-forgotten mathematical link, buried in obscure…

My posts last week created a lot of unnecessary confusion*, so today I would like to do a deep dive on one example to explain why I was so excited. In short, it’s not about AIs discovering new results on their own, but rather how tools like GPT-5 can help researchers navigate,…


I used ChatGPT to solve an open problem in convex optimization. *Part I* (1/N)

I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter. The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language…

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…




Replicate IMO-Gold in less than 500 lines: gist.github.com/faabian/39d057… The prover-verifier workflow from Huang & Yang: Winning Gold at IMO 2025 with a Model-Agnostic Verification-and-Refinement Pipeline (arxiv.org/abs/2507.15855), original code at github.com/lyang36/IMO25/

Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…


When should an LLM learn to reason? 🤔 Early in pretraining or late in fine-tuning? Our new work, "Front-Loading Reasoning", challenges the "save it for later" approach. We show that injecting reasoning data into pretraining is critical for building models that reach the…


New paper 📜: Tiny Recursion Model (TRM) is a recursive reasoning approach with a tiny 7M parameters neural network that obtains 45% on ARC-AGI-1 and 8% on ARC-AGI-2, beating most LLMs. Blog: alexiajm.github.io/2025/09/29/tin… Code: github.com/SamsungSAILMon… Paper: arxiv.org/abs/2510.04871

My brain broke when I read this paper. A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2. It's called Tiny Recursive Model (TRM) from Samsung. How can a model 10,000x smaller be smarter? Here's how…


A beautiful paper from MIT+Harvard+ @GoogleDeepMind 👏 Explains why Transformers miss multi digit multiplication and shows a simple bias that fixes it. The researchers trained two small Transformer models on 4-digit-by-4-digit multiplication. One used a special training method…


Very interesting result! Though perhaps not too surprising if you recall that RL-tuned models often show much smaller feature shifts than SFT (see e.g. Xiang’s post below). When the model doesn’t have to move very far, LoRA—or even something lighter—can already do the job. As…

LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…


Meta AI’s new paper shows that strong chain-of-thought reasoning can emerge in models under 1 billion parameters if you feed them the right data. Key takeaways 🔹Smaller, smarter. MobileLLM-R1 (140 M – 950 M params) beats or matches prior open-source peers on reasoning suites…


LoRA in reinforcement learning (RL) can match full-finetuning performance when done right! 💡 A new @thinkymachines post shows how using 10x larger learning rates, applying LoRA on all layers & more, LoRA at rank=1 even works. We're excited to have collaborated on this blog!
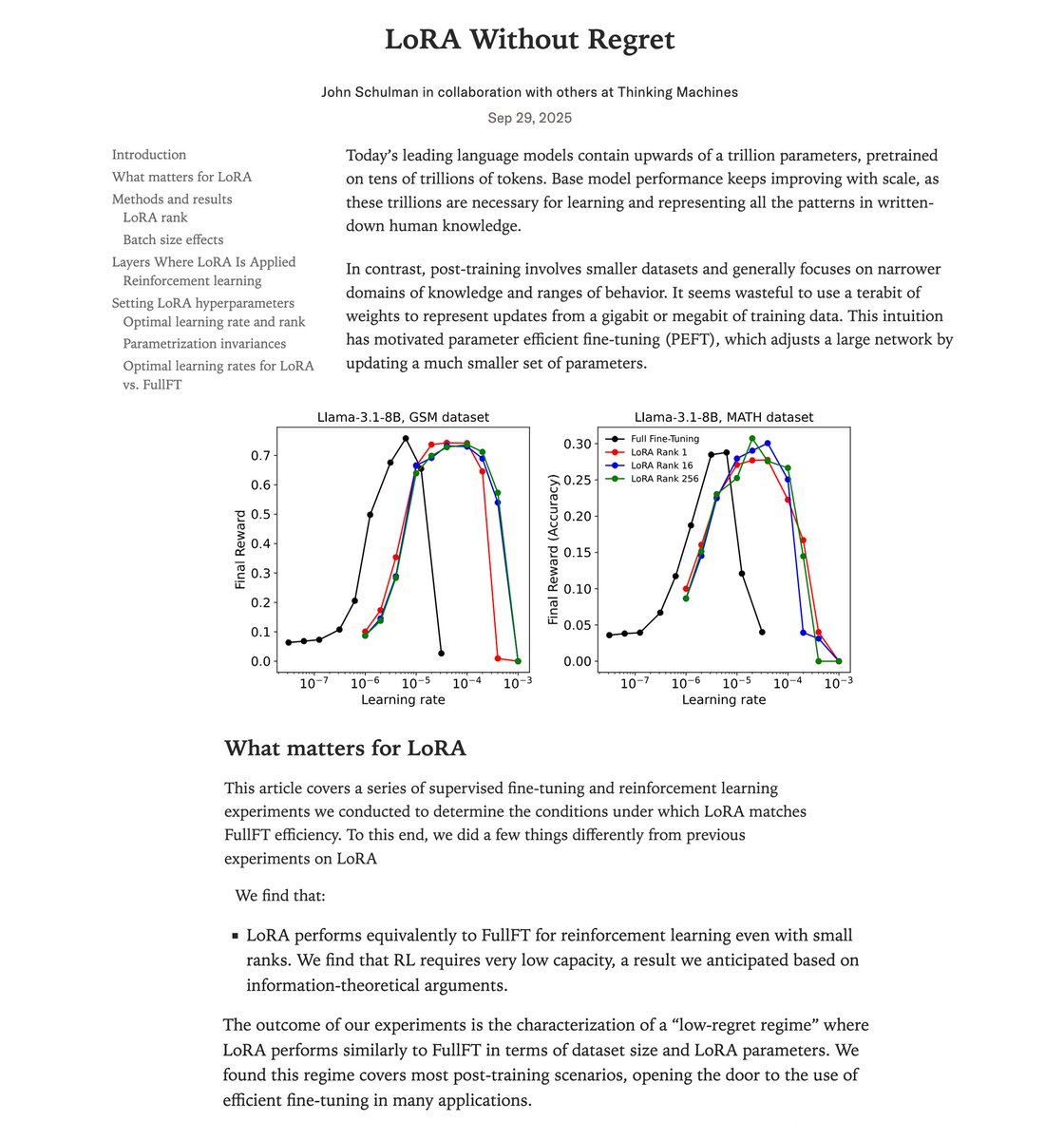
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…

Great work showing prompt synthesis as a new scaling axis for reasoning. Good training data is scarce. This work showcases a framework that might make it possible to construct high-quality training problems for reasoning-focused LLMs. Technical details below:

Yet more evidence that a pretty major shift is happening, this time by Scott Aaronson scottaaronson.blog/?p=9183&fbclid…


I have a new blog post about the so-called “tokenizer-free” approach to language modeling and why it’s not tokenizer-free at all. I also talk about why people hate tokenizers so much!


Damn, very interesting paper. after rapid loss reduction, we see deceleration and follow "scaling law": this is because at these steps, gradients start to conflict each other. Updates are 'fightining for modal capacity' in some sense, and larger the model less fighting there…


Correct! Just as a reminder: this is what a Transformer found after looking at 10M solar systems
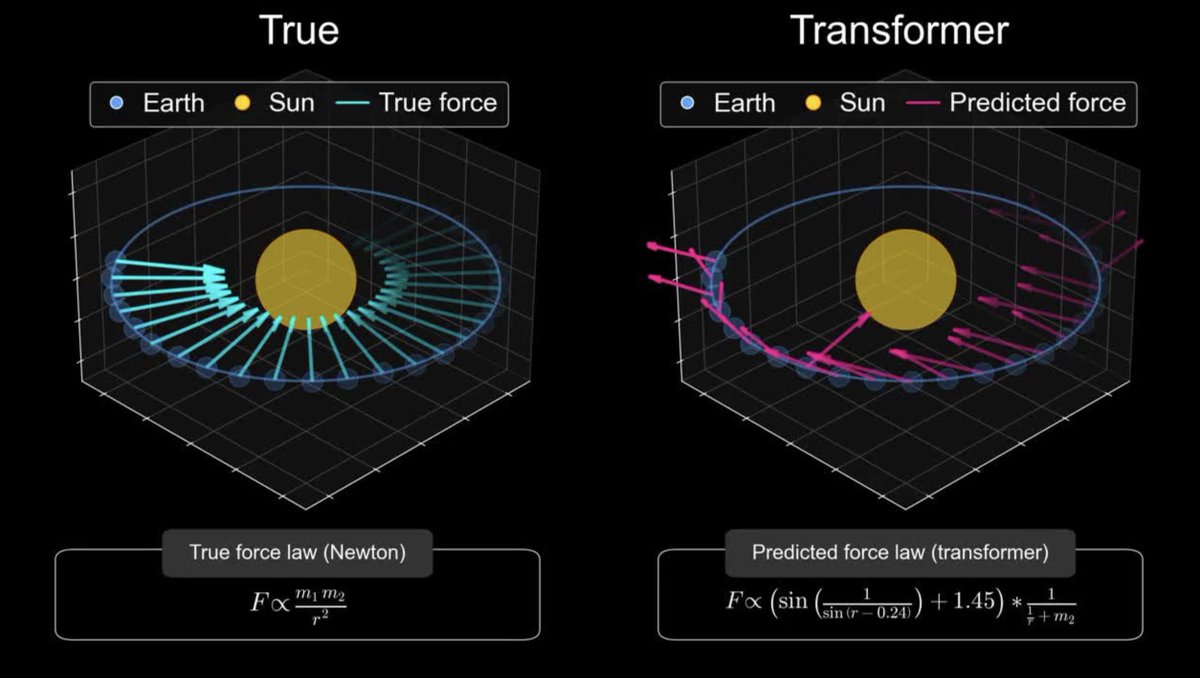

A student who truly understands F=ma can solve more novel problems than a Transformer that has memorized every physics textbook ever written.







































































United States الاتجاهات
- 1. Austin Reaves 57.4K posts
- 2. #LakeShow 3,349 posts
- 3. Trey Yesavage 39.5K posts
- 4. jungkook 559K posts
- 5. Jake LaRavia 6,940 posts
- 6. Jeremy Lin 1,034 posts
- 7. #LoveIsBlind 4,762 posts
- 8. Happy Birthday Kat N/A
- 9. jungwoo 119K posts
- 10. #Lakers 1,226 posts
- 11. Rudy 9,405 posts
- 12. Blue Jays 63K posts
- 13. doyoung 87K posts
- 14. Kacie 1,956 posts
- 15. Pelicans 4,628 posts
- 16. #SellingSunset 3,991 posts
- 17. #AEWDynamite 23.9K posts
- 18. KitKat 17.6K posts
- 19. Devin Booker 1,346 posts
- 20. Dodgers in 7 1,697 posts
Something went wrong.
Something went wrong.