
Jongsu Liam Kim
@sky0bserver
The CFD enthusiast has become a ML researcher. Senior Researcher at LG CNS AI Lab. Opinions are solely my own and do not express the opinions of my employer.
You might like













tfw you find a good cuda blog that you can actually follow along and reproduce the results because it’s optimized for your gpu arch


The most intuitive explanation of floats I've ever come across, courtesy of @fabynou fabiensanglard.net/floating_point…


Optimizing Attention on GPUs by Exploiting GPU Architectural NUMA Effects Swizzled Head-first Mapping cuts attention latency on chiplet GPUs by making scheduling NUMA-aware. It maps all row-blocks of a head (or KV-group in GQA) to the same XCD, so K/V first-touch stays hot in…


🔥 New Blog: “Disaggregated Inference: 18 Months Later” 18 months in LLM inference feels like a new Moore’s Law cycle – but this time not just 2x per year: 💸 Serving cost ↓10–100x 🚀 Throughput ↑10x ⚡ Latency ↓5x A big reason? Disaggregated Inference. From DistServe, our…


Please register here: luma.com/9n27uem4 Like previous competitions, this competition will take place on the GPU MODE Discord server. More information can be found on the registration link. Good luck to all competitors!


Inspired by @thinkymachines 's "#LoRA Without Regret" post, I formalized their insight that policy gradient learns ~1 bit per episode via Bayesian #RL formulation. I prove this is a hard information-theoretic ceiling and extend the analysis to actor-critic methods. Full writeup…


LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…


This remote memory (NVMe over NVLink at full MBU) may also be of interest weka.io/blog/ai-ml/unl…


I think programming GPUs is too hard. Part of the problem is sprawling, scattered documentation & best practices. Over the past few months, we’ve been working to solve that problem, putting together a “Rosetta Stone” GPU Glossary. And now it’s live! My take-aways in thread.


We’ve cooked another one of these 200+ pages practical books on model training that we love to write. This time it’s on all pretraining and post-training recipes and how to do a training project hyper parameter exploration. Closing the trilogy of: 1. Building a pretraining…

Training LLMs end to end is hard. Very excited to share our new blog (book?) that cover the full pipeline: pre-training, post-training and infra. 200+ pages of what worked, what didn’t, and how to make it run reliably huggingface.co/spaces/Hugging…


Very nice blog post from Thinky (@_kevinlu et al) about on-policy distillation for LLMs -- we published this idea back in 2023 and it is *publicly* known to be successfully applied to Gemma 2 & 3, and Qwen3-Thinking (and probably many closed frontier models)! The idea behind…
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…
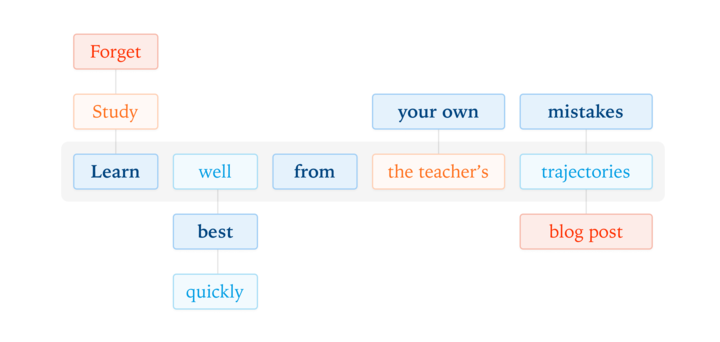

I remember discussing this with @SeunghyunSEO7 literally 2 years ago. Time flies!!!


Please pay me 100m to convert papers like openreview.net/pdf?id=3zKtaqx… to blogposts! @agarwl_

🧵 LoRA vs full fine-tuning: same performance ≠ same solution. Our NeurIPS ‘25 paper 🎉shows that LoRA and full fine-tuning, even when equally well fit, learn structurally different solutions and that LoRA forgets less and can be made even better (lesser forgetting) by a simple…


A small thread about how you should be drawing the contents of higher dimensional tensors


Reading through Torchcomms paper, there are a few nice features it introduces It defaults to zero copy transfer for comms. With copy-based transfers, it uses SM / HBM memory on GPU and maintains a small FIFO queue to transfer data. This can introduce some overhead + contention…



Excited to share our new work: StreamingVLM! 🚀 We tackle a major challenge for Vision-Language Models (VLMs): understanding infinite video streams in real-time without latency blowing up or running out of memory. Paper: arxiv.org/abs/2510.09608 Code: github.com/mit-han-lab/st…

Will present automatically derived kernels to @GPU_MODE noon PST Saturday. Got to @MIT in September, been grinding maths w/ @GioeleZardini to ensure universal applicability across models and hardware. Hierarchical kernels, encoding, optimization. This is gonna be good.


6 months after our paper release, I still recall the debates on removing the length normalization term in DrGRPO. And people gradually think DrGRPO is just about removing the std, ignoring the most important and subtle (length) bias we tried to point out to the community. Even…


I have written another blogpost that is so pretty: covering kernels, graphics, profiling, etc. etc. ut21.github.io/blog/triton.ht…



Even with full-batch gradients, DL optimizers defy classical optimization theory, as they operate at the *edge of stability.* With @alex_damian_, we introduce "central flows": a theoretical tool to analyze these dynamics that makes accurate quantitative predictions on real NNs.





























































































United States Trends
- 1. Max B 10.6K posts
- 2. Alec Pierce 1,873 posts
- 3. Kyle Pitts 1,016 posts
- 4. Bijan 2,164 posts
- 5. Penix 1,719 posts
- 6. Badgley N/A
- 7. #Colts 2,215 posts
- 8. Zac Robinson N/A
- 9. #ForTheShoe 1,317 posts
- 10. #Talus_Labs N/A
- 11. $LMT $450.50 Lockheed F-35 N/A
- 12. $SENS $0.70 Senseonics CGM N/A
- 13. Good Sunday 74K posts
- 14. #Falcons 1,189 posts
- 15. Tyler Allgeier N/A
- 16. Dee Alford N/A
- 17. $APDN $0.20 Applied DNA N/A
- 18. #AskFFT N/A
- 19. JD Bertrand N/A
- 20. Cam Bynum N/A











Something went wrong.
Something went wrong.