
Wenting Zhao
@wzhao_nlp
reasoning & llms @Alibaba_Qwen Opinions are my own
คุณอาจชื่นชอบ















Team Eric 🫡

.@ericzelikman & 7th Googler @gharik are raising $1b for an AI lab called Humans&. I'm told Eric's paper STaR was an inspiration for OpenAI's reasoning models, and that he was also one of the star AI researchers labs fought over. forbes.com/sites/annatong…

Many people are confused by Minimax’s recent return to full attention - especially since it was the first large-scale pivot toward hybrid linear attention - and by Kimi’s later adoption of hybrid linear variants (as well as earlier attempts by Qwen3-Next, or Qwen3.5). I actually…

MiniMax M2 Tech Blogs on Huggingface: 1. huggingface.co/blog/MiniMax-A… 2. huggingface.co/blog/MiniMax-A… 3. huggingface.co/blog/MiniMax-A…

MiniMax M2 Tech Blog 3: Why Did M2 End Up as a Full Attention Model? On behave of pre-training lead Haohai Sun. (zhihu.com/question/19653…) I. Introduction As the lead of MiniMax-M2 pretrain, I've been getting many queries from the community on "Why did you turn back the clock…
If you happen to be in Shanghai next Monday, come hang out with us 🤩

We will have a pre-EMNLP workshop about LLMs next Monday at @nyushanghai campus! Speakers are working on diverse and fantastic problems, really looking forward to it! We also provide a zoom link for those who cannot join in person :) (see poster)


One personal reflection is how interesting a challenge RL is. Unlike other ML systems, you can't abstract much from the full-scale system. Roughly, we co-designed this project and Cursor together in order to allow running the agent at the necessary scale.

Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on! 📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon. It traces the core…

The question I got asked most frequently during COLM this year was what research questions can be studied in academia that will also be relevant to frontier labs. So I’m making a talk for this. What topics / areas should I cover? RL/eval/pretraining,?

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

Cursor team is stacked on X, shortlist for insider updates: • @ryolu_ - design • @ericzakariasson - dev rel • @TheRohanVarma - product • @leerob - dev rel • @JuanRezzio - QA engineering • @davidrfgomes - engineering • @austinnickpiel - engineering • @milichab - product…

🌶️SPICE: Self-Play in Corpus Environments🌶️ 📝: arxiv.org/abs/2510.24684 - Challenger creates tasks based on *corpora* - Reasoner solves them - Both trained together ⚔️ -> automatic curriculum! 🔥 Outperforms standard (ungrounded) self-play Grounding fixes hallucination & lack of…


it’s tokenization again! 🤯 did you know tokenize(detokenize(token_ids)) ≠ token_ids? RL researchers from Agent Lightning coined the term Retokenization Drift — a subtle mismatch between what your model generated and what your trainer thinks it generated. why? because most…

youtube.com
YouTube
Let's build the GPT Tokenizer

Below is a deep dive into why self play works for two-player zero-sum (2p0s) games like Go/Poker/Starcraft but is so much harder to use in "real world" domains. tl;dr: self play converges to minimax in 2p0s games, and minimax is really useful in those games. Every finite 2p0s…

Self play works so well in chess, go, and poker because those games are two-player zero-sum. That simplifies a lot of problems. The real world is messier, which is why we haven’t seen many successes from self play in LLMs yet. Btw @karpathy did great and I mostly agree with him!
People ask about how to be hired by frontier labs? Understand and be able to produce every detail👇

Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…


Talk from Wenting Zhao of Qwen on their plans during COLM. Seems like 1 word is the plan still: scaling training up! Let’s go.

I was really looking forward to be at #COLM2025 with Junyang, but visa takes forever 😞 come ask me about Qwen: how is it like to work here, what features you’d like to see, what bugs you’d like us to fix, or anything!

Sorry about missing COLM due to my failure in my VISA application. @wzhao_nlp will be there and represent Qwen to give a speech and discuss on the panel about reasoning and agents!
Want to hear some hot takes about the future of language modeling, and share your takes too? Stop by the Visions of Language Modeling workshop at COLM on Friday, October 10 in room 519A! There will be over a dozen speakers working on all kinds of problems in modeling language and…


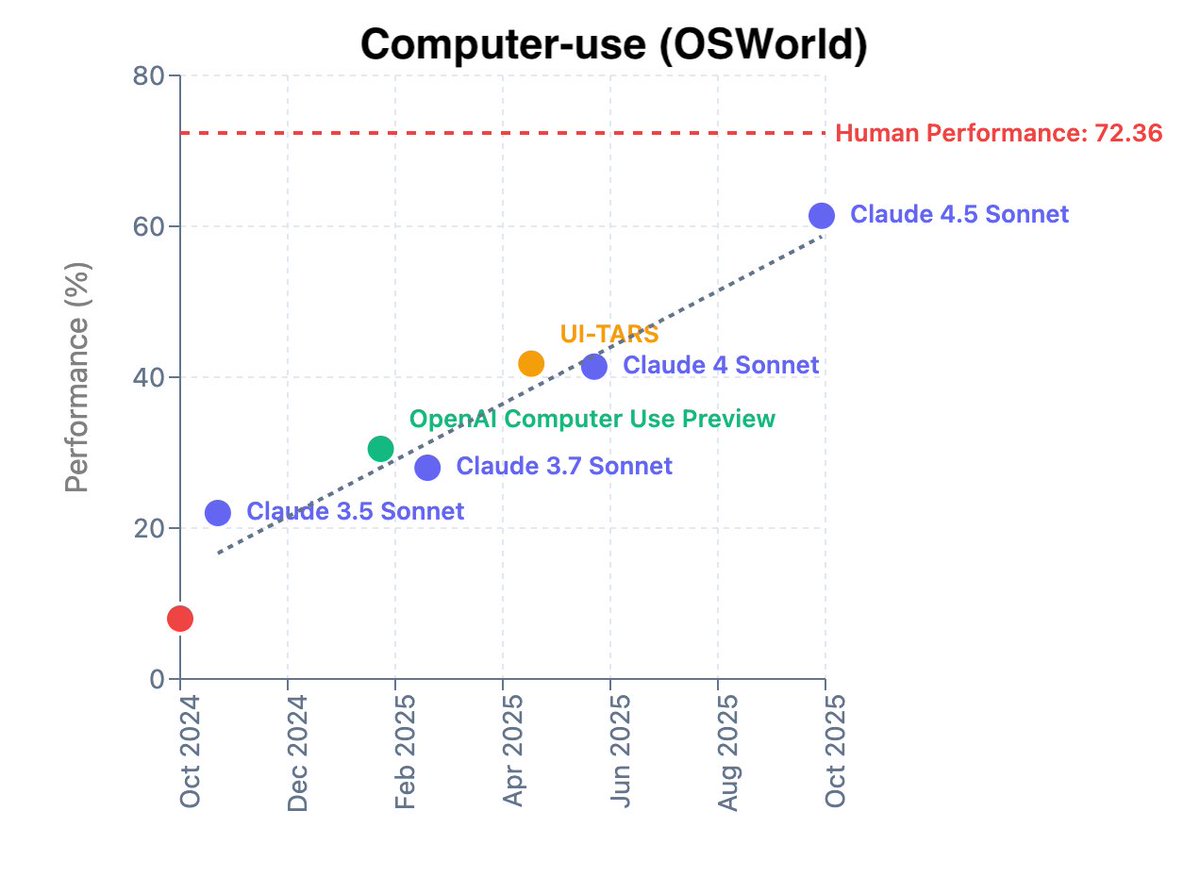
When @ethansdyer and I joined Anthropic last Dec and spearheaded the discovery team, we decided to focus on unlocking computer-use as a bottleneck for scientific discovery. It has been incredible to work on improving computer-use and witness the fast progress. In OSWorld for…

🚨Modeling Abstention via Selective Help-seeking LLMs learn to use search tools to answer questions they would otherwise hallucinate on. But can this also teach them what they know vs not? @momergul_ introduces MASH that trains LLMs for search and gets abstentions for free!…

Really excited and proud to see Qwen models are in the first batch of supported models for the tinker service! 🤩 we will continue to release great models to grow research in the community 😎

Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!…


The most surprising thing working on this was that RL with LoRA completely matches full training and develops the same extended reasoning patterns. I think this is a great sign for custom agent training.
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…






























































































United States เทรนด์
- 1. New York 1.27M posts
- 2. Neal Katyal 1,357 posts
- 3. #questpit 22.4K posts
- 4. Van Jones 9,172 posts
- 5. Lina Khan 1,803 posts
- 6. IEEPA 3,078 posts
- 7. Sauer 4,662 posts
- 8. 5th of November 24.2K posts
- 9. #5SOS_SELFIEDAY N/A
- 10. Gorsuch 3,814 posts
- 11. Miss Piggy 3,743 posts
- 12. #wednesdaymotivation 2,960 posts
- 13. Alito 8,795 posts
- 14. Alastor 51.5K posts
- 15. The GOP 324K posts
- 16. Mississippi 29.1K posts
- 17. Godzilla 19.9K posts
- 18. Hump Day 18.9K posts
- 19. #Wednesdayvibe 2,226 posts
- 20. Balmain 4,517 posts
คุณอาจชื่นชอบ
-
 Yuntian Deng @EMNLP 2025
Yuntian Deng @EMNLP 2025
@yuntiandeng -
 Zhaofeng Wu ✈️ EMNLP
Zhaofeng Wu ✈️ EMNLP
@zhaofeng_wu -
 Yu Feng
Yu Feng
@AnnieFeng6 -
 Hamish Ivison
Hamish Ivison
@hamishivi -
 Prasann Singhal
Prasann Singhal
@prasann_singhal -
 Yuling Gu
Yuling Gu
@gu_yuling -
 Chenghao Yang
Chenghao Yang
@chrome1996 -
 Belinda Li
Belinda Li
@belindazli -
 Zhaowei Wang
Zhaowei Wang
@ZhaoweiWang4 -
 Joongwon Kim
Joongwon Kim
@danieljwkim -
 Kyle Lo
Kyle Lo
@kylelostat -
 Songlin Yang
Songlin Yang
@SonglinYang4 -
 Ian Magnusson
Ian Magnusson
@IanMagnusson -
 Nishant Subramani @ EMNLP
Nishant Subramani @ EMNLP
@nsubramani23 -
 Swarnadeep Saha
Swarnadeep Saha
@swarnaNLP
Something went wrong.
Something went wrong.