#distributedtraining 검색 결과

Communication is often the bottleneck in distributed AI. Gensyn’s CheckFree offers a fault-tolerant pipeline method that yields up to 1.6× speedups with minimal convergence loss. @gensynai #AI #DistributedTraining


Data from block 3849132 (a second ago) --------------- 💎🚀 Subnet32 emission has changed from 2.587461% to 2.5954647% #bittensor #decentralizedAI #distributedtraining $tao #subnet @ai_detection


RT Training BERT at a University dlvr.it/RnRh2T #distributedsystems #distributedtraining #opensource #deeplearning


I'm wondering if an Autoregressive Language Model could run on something like the #EthereumVirtualMachine. 🤔 Would that remedy the bottlenecking problem of #DistributedTraining on a #PeerToPeerNetwork of mixed nodes & GPUs? If so, how much would that speed up training?



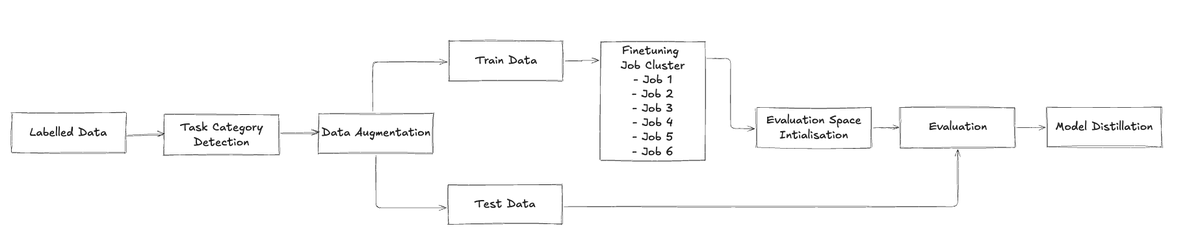
System Architecture Overview The system has two subsystems: • Data Processing – Manages data acquisition, enhancement, and quality checks. • #DistributedTraining – Oversees parallel fine-tuning, resource allocation, and evaluation. This division allows independent scaling,…

Elevate your #ML projects with our AI Studio’s Training Jobs—designed for seamless scalability and real-time monitoring. Support for popular frameworks like PyTorch, TensorFlow, and MPI ensures effortless #distributedtraining. Key features include: ✨ Distributed Training: Run…


✅ Achievement Unlocked! Efficient #distributedtraining of #DeepSeek-R1:671B is realized on #openEuler 24.03! Built for the future of #AI, openEuler empowers #developers to push the boundaries of innovation. 🐋Full technical deep dive coming soon! @deepseek_ai #opensource #LLM


Skimmed over #XGBoost4J's source code for #DistributedTraining using #xgboost to learn more about...Barrier Scheduling in #ApacheSpark 💪 ➡️ books.japila.pl/apache-spark-i… There's still a lot to do Spark-wise in xgboost4j-spark to use Spark-native barrier/allGather IMHO.



Distributed Training in ICCLOUD's Layer 2 with Horovod + Mixed - Precision. Cuts training costs by 40%. Cost - effective training! #DistributedTraining #CostSaving


🚀 Introducing Asteron LM – a distributed training platform built for the ML community. PS: Website coming soooon !! #FutureOfAI #OpenAICommunity #DistributedTraining #Startup #buildinpublic #indiehackers #aiforall #DemocratizingAI
RT Cost Efficient Distributed Training with Elastic Horovod and Amazon EC2 Spot Instances dlvr.it/RslZnC #elastic #amazonec2 #distributedtraining #horovod #deeplearning


DeepSpeed makes distributed training feel like magic. What took 8 GPUs now runs on 2. Gradient accumulation and model sharding just work out of the box. #DeepSpeed #DistributedTraining #Python
RT Single line distributed PyTorch training on AWS SageMaker dlvr.it/RjStv7 #distributedtraining #pytorch #sagemaker #datascience #deeplearning

RT Speed up EfficientNet training on AWS by up to 30% with SageMaker Distributed Data Parallel Library dlvr.it/SH12hL #sagemaker #distributedtraining #deeplearning #computervision #aws

Distributed training just got easier on Outerbounds! Now generally available, it supports multi-GPU setups with [@]torchrun and [@]metaflow_ray. Perfect for large data and models. Train efficiently, even at scale! 💡 #AI #DistributedTraining
![OuterboundsHQ's tweet image. Distributed training just got easier on Outerbounds! Now generally available, it supports multi-GPU setups with [@]torchrun and [@]metaflow_ray. Perfect for large data and models. Train efficiently, even at scale! 💡 #AI #DistributedTraining](https://pbs.twimg.com/media/GX2qQi9WcAALkzc.jpg)
RT Distributed Parallel Training — Model Parallel Training dlvr.it/SYG4xb #machinelearning #distributedtraining #largemodeltraining


Day 27 of #100DaysOfCode: 🌟 Today, I coded for Distributed Training! 🖥️ 🔄 Even without multiple CPUs, I learned how to scale deep learning models across devices. Excited to apply this knowledge in future projects! #DistributedTraining #DeepLearning #AI

Here’s the post: 🔗 medium.com/@jenwei0312/th… If it stops one person from quitting distributed training — mission complete. ❤️🔥 #AIResearch #DistributedTraining #LLM #PyTorch #DeepLearning #MuonOptimizer #ResearchJourney #ZeRO #TensorParallel #FSDP #OpenSourceAI
medium.com
The “Turtle Speed” Breakthrough 🐢✨, Part 3: My Map of the Distributed Nightmare
From “Headache” to “Blueprint”
RT Smart Distributed Training on Amazon SageMaker with SMD: Part 2 dlvr.it/SYkhMQ #sagemaker #horovod #distributedtraining #machinelearning #tensorflow

RT Smart Distributed Training on Amazon SageMaker with SMD: Part 3 dlvr.it/SYktJ4 #distributedtraining #machinelearning #deeplearning #sagemaker

Here’s the post: 🔗 medium.com/@jenwei0312/th… If it stops one person from quitting distributed training — mission complete. ❤️🔥 #AIResearch #DistributedTraining #LLM #PyTorch #DeepLearning #MuonOptimizer #ResearchJourney #ZeRO #TensorParallel #FSDP #OpenSourceAI
medium.com
The “Turtle Speed” Breakthrough 🐢✨, Part 3: My Map of the Distributed Nightmare
From “Headache” to “Blueprint”
DeepSpeed makes distributed training feel like magic. What took 8 GPUs now runs on 2. Gradient accumulation and model sharding just work out of the box. #DeepSpeed #DistributedTraining #Python
Communication is often the bottleneck in distributed AI. Gensyn’s CheckFree offers a fault-tolerant pipeline method that yields up to 1.6× speedups with minimal convergence loss. @gensynai #AI #DistributedTraining
The best platform for autoML #distributedtraining I've ever seen.

Remember that everyone outside of Bittensor and even those holding $TAO hoping for a lower entry on 56 alpha will shun these achievements. They are incentivized to. We know the truth; @gradients_ai is the best performing, fastest improving and lowest cost AutoML platform ever.

Custom Slurm clusters deploy in 37 seconds. Orchestrate multi-node training jobs with H100s at $3.58/GPU/hr. Simplify distributed AI. get.runpod.io/oyksj6fqn1b4 #Slurm #DistributedTraining #HPC #AIatScale


⚡️ As AI model parameters reach into the billions, Bittensor's infrastructure supports scalable, decentralized training—making artificial general intelligence more attainable through global, collaborative efforts rather than isolated labs. #AGI #DistributedTraining

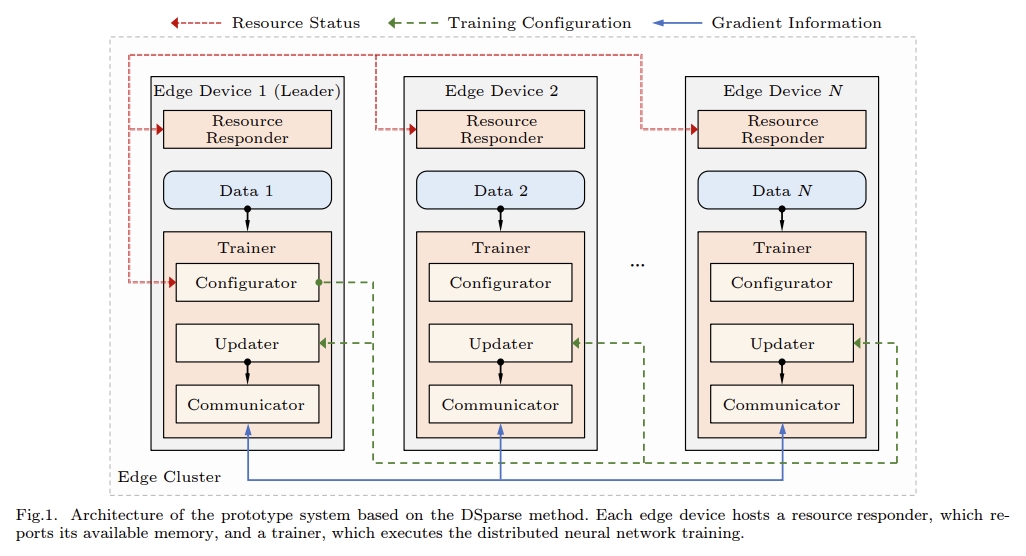
DSparse: A Distributed Training Method for Edge Clusters Based on Sparse Update jcst.ict.ac.cn/article/doi/10… #DistributedTraining #EdgeComputing #MachineLearning #SparseUpdate #EdgeCluster #Institute_of_Computing_Technology @CAS__Science @UCAS1978

Distributed Training: Train massive AI models without massive bills! Akash Network's decentralized GPU marketplace cuts costs by up to 10x vs traditional clouds. Freedom from vendor lock-in included 😉 #MachineLearning #DistributedTraining #CostSavings $AKT $SPICE

📚 Blog: pgupta.info/blog/2025/07/d… 💻 Code: github.com/pg2455/distrib… I wrote this to understand the nuts and bolts of LLM infra — If you're on the same path, this might help. #PyTorch #LLMEngineering #DistributedTraining #MLInfra

12/20Learn distributed training frameworks: Horovod, PyTorch Distributed, TensorFlow MultiWorkerStrategy. Single-GPU training won't cut it for enterprise models. Model parallelism + data parallelism knowledge is essential. #DistributedTraining #PyTorch #TensorFlow
12/20Learn distributed training frameworks: Horovod, PyTorch Distributed, TensorFlow MultiWorkerStrategy. Single-GPU training won't cut it for enterprise models. Model parallelism + data parallelism knowledge is essential. #DistributedTraining #PyTorch #TensorFlow
7/20Learn distributed training early. Even "small" LLMs need multiple GPUs. Master PyTorch DDP, gradient accumulation, and mixed precision training. These skills separate hobbyists from professionals. #DistributedTraining #Scaling #GPU
Distributed Training in ICCLOUD's Layer 2 with Horovod + Mixed - Precision. Cuts training costs by 40%. Cost - effective training! #DistributedTraining #CostSaving
Communication is often the bottleneck in distributed AI. Gensyn’s CheckFree offers a fault-tolerant pipeline method that yields up to 1.6× speedups with minimal convergence loss. @gensynai #AI #DistributedTraining
Data from block 3849132 (a second ago) --------------- 💎🚀 Subnet32 emission has changed from 2.587461% to 2.5954647% #bittensor #decentralizedAI #distributedtraining $tao #subnet @ai_detection
RT Training BERT at a University dlvr.it/RnRh2T #distributedsystems #distributedtraining #opensource #deeplearning
I'm wondering if an Autoregressive Language Model could run on something like the #EthereumVirtualMachine. 🤔 Would that remedy the bottlenecking problem of #DistributedTraining on a #PeerToPeerNetwork of mixed nodes & GPUs? If so, how much would that speed up training?
Elevate your #ML projects with our AI Studio’s Training Jobs—designed for seamless scalability and real-time monitoring. Support for popular frameworks like PyTorch, TensorFlow, and MPI ensures effortless #distributedtraining. Key features include: ✨ Distributed Training: Run…

This article reviews recently developed methods that focus on #distributedtraining of large-scale #machinelearning models from streaming data in the compute-limited and bandwidth-limited regimes. bit.ly/37i4QBo
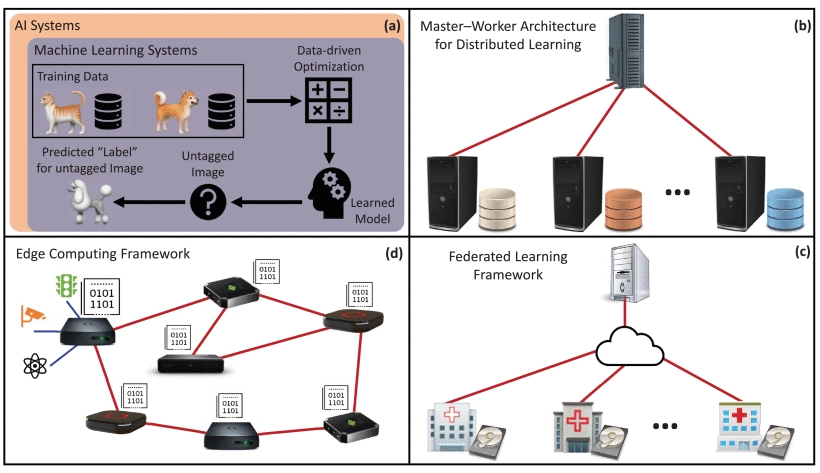

@PLEXSYS Releases #ASCOT 7.2 with New Features #innovation #DistributedTraining #simulationsinscenarios #syntheticenvironment plexsys.com/general-inform…
Distributed Training in ICCLOUD's Layer 2 with Horovod + Mixed - Precision. Cuts training costs by 40%. Cost - effective training! #DistributedTraining #CostSaving

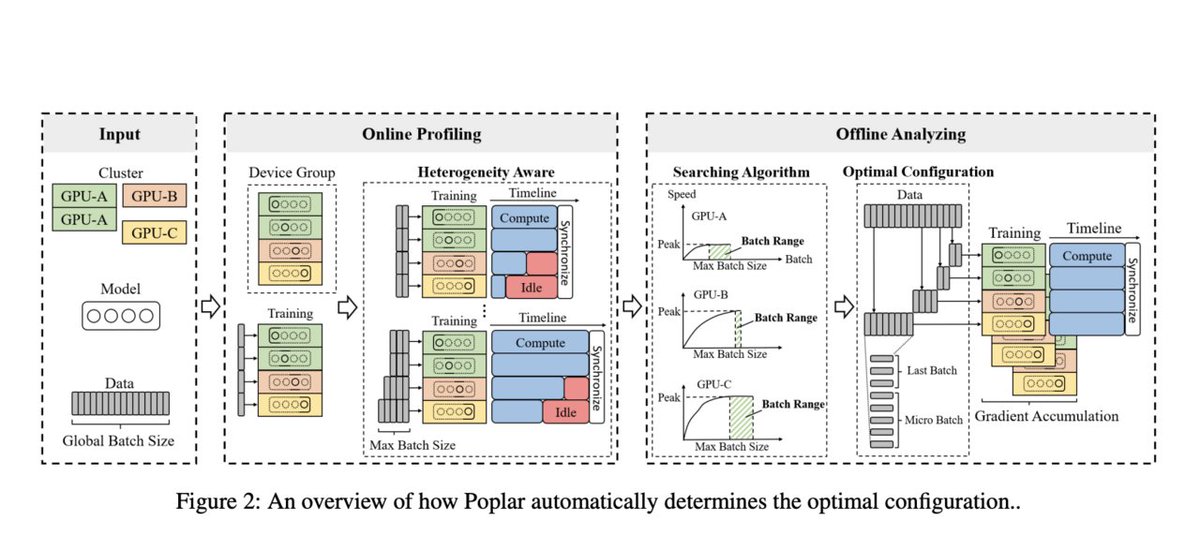
Poplar: A Distributed Training System that Extends Zero Redundancy Optimizer (ZeRO) with Heterogeneous-Aware Capabilities itinai.com/poplar-a-distr… #AI #DistributedTraining #HeterogeneousGPUs #ArtificialIntelligence #Poplar #ai #news #llm #ml #research #ainews #innovation #arti…
RT Speed up EfficientNet training on AWS by up to 30% with SageMaker Distributed Data Parallel Library dlvr.it/SH12hL #sagemaker #distributedtraining #deeplearning #computervision #aws
System Architecture Overview The system has two subsystems: • Data Processing – Manages data acquisition, enhancement, and quality checks. • #DistributedTraining – Oversees parallel fine-tuning, resource allocation, and evaluation. This division allows independent scaling,…
RT Single line distributed PyTorch training on AWS SageMaker dlvr.it/RjStv7 #distributedtraining #pytorch #sagemaker #datascience #deeplearning
RT Distributed Parallel Training — Model Parallel Training dlvr.it/SYG4xb #machinelearning #distributedtraining #largemodeltraining
✅ Achievement Unlocked! Efficient #distributedtraining of #DeepSeek-R1:671B is realized on #openEuler 24.03! Built for the future of #AI, openEuler empowers #developers to push the boundaries of innovation. 🐋Full technical deep dive coming soon! @deepseek_ai #opensource #LLM
RT Cost Efficient Distributed Training with Elastic Horovod and Amazon EC2 Spot Instances dlvr.it/RslZnC #elastic #amazonec2 #distributedtraining #horovod #deeplearning
DSparse: A Distributed Training Method for Edge Clusters Based on Sparse Update jcst.ict.ac.cn/article/doi/10… #DistributedTraining #EdgeComputing #MachineLearning #SparseUpdate #EdgeCluster #Institute_of_Computing_Technology @CAS__Science @UCAS1978
RT Smart Distributed Training on Amazon SageMaker with SMD: Part 2 dlvr.it/SYkhMQ #sagemaker #horovod #distributedtraining #machinelearning #tensorflow
RT Smart Distributed Training on Amazon SageMaker with SMD: Part 3 dlvr.it/SYktJ4 #distributedtraining #machinelearning #deeplearning #sagemaker
RT Distributed Parallel Training: Data Parallelism and Model Parallelism dlvr.it/SYbnML #modelparallelism #distributedtraining #pytorch #dataparallelism

RT Effortless distributed training for PyTorch models with Azure Machine Learning and… dlvr.it/SHTbMx #azuremachinelearning #distributedtraining #pytorch #mlsogood
Something went wrong.
Something went wrong.
United States Trends
- 1. Marshawn Kneeland 21.1K posts
- 2. Nancy Pelosi 25.4K posts
- 3. #MichaelMovie 35.1K posts
- 4. #NO1ShinesLikeHongjoong 26.6K posts
- 5. #영원한_넘버원캡틴쭝_생일 26.3K posts
- 6. ESPN Bet 2,299 posts
- 7. Gremlins 3 2,896 posts
- 8. #thursdayvibes 2,954 posts
- 9. Jaafar 10.7K posts
- 10. Chimecho 5,229 posts
- 11. Baxcalibur 3,635 posts
- 12. Joe Dante N/A
- 13. Madam Speaker 1,013 posts
- 14. Chris Columbus 2,586 posts
- 15. Good Thursday 36.2K posts
- 16. #LosdeSiemprePorelNO N/A
- 17. Votar No 26.8K posts
- 18. Penn 9,225 posts
- 19. Korrina 4,173 posts
- 20. Diantha 1,479 posts