#textdata نتائج البحث

Introducing the fresh Assamese Corpus on Sketch Engine! Dive into 2.5 million words of Assamese (Asamiya), an Indo-Aryan language spoken in Assam, India. It's cleaned, deduplicated, and ready for your linguistic exploration. #textdata #LanguageAnalysis sketchengine.eu/assamese-corpu…


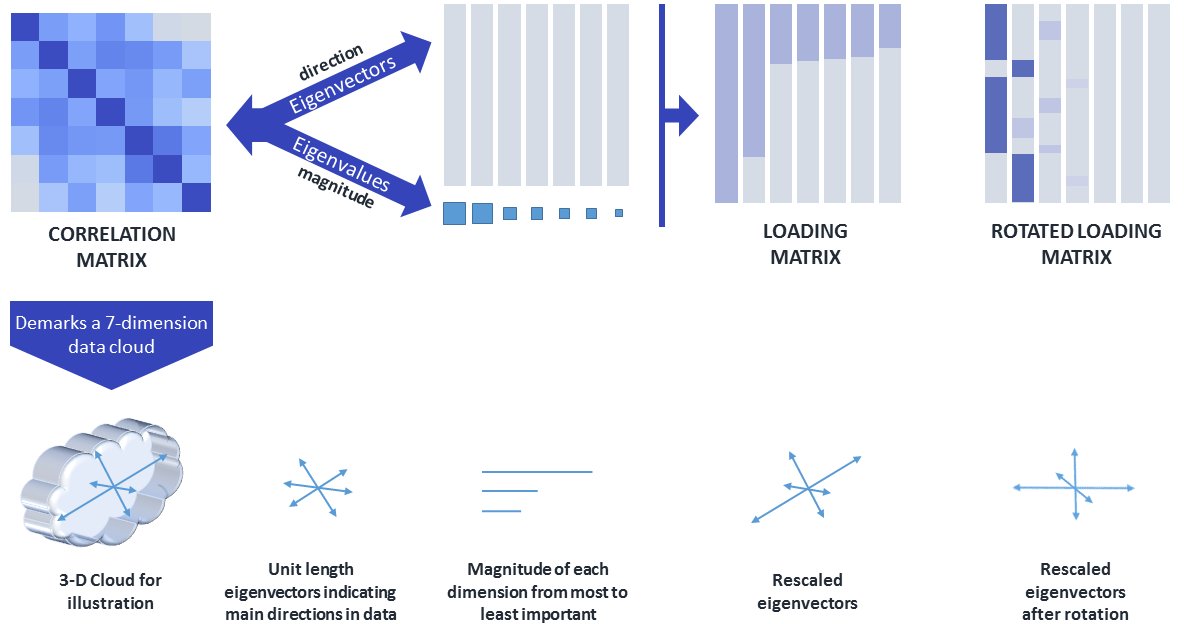
I decided to convert our paper on #textdata and #twitter into a poster using #rstats package #posterdown @hdcripps @mejtoft @rforresearch. Have a read of the full paper which is #openaccess as this infographics only shows #textmining results. Thx @wbrentthorne for the package!


If you have #TextData but haven't gotten around learning how to analyze them, this Medium article can help get you started by breaking through the computer science jargon. You might already know more #TextAnalytics than you think! link.medium.com/sVvk7oWFshb

5 NLP libraries for working with Text data ! #nlp #libraries #textdata #genism #textblob #spacy #corenlp #python #data #datascience #machinelearning #ai #deeplearning #analytics #dataanalytics #bitscrunch P.S - DatumGuy




New #preprint: "The Latent Topic Block Model for the #CoClustering of Textual Interaction Data" w/ @latouche_pierre @Marco_Corneli @lrberge #TextData #RecommenderSystems hal.archives-ouvertes.fr/hal-01835074


Following our recent update for Lithuanian, we’re introducing the new Lithuanian Web corpus 2021! It's lemmatized, part-of-speech tagged, and classified by genres and topics. #corpuslinguistics #digitalhumanities #textdata sketchengine.eu/lttenten-lithu…


Relative Health is finally here! ⚕️🚑 Are you a healthcare specialist looking to do more with your #textdata? Read about this pioneering #textanalytics solution created specifically for pharmaceutical, healthcare, biotech and medical device companies: eu1.hubs.ly/H02wD140





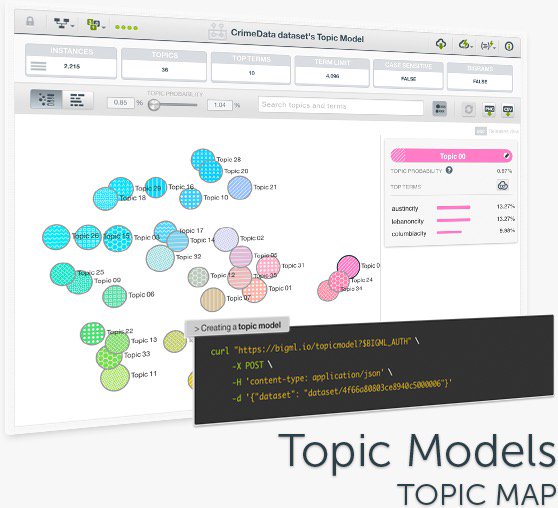
Learn how to find thematically related terms in your #TextData with #TopicModels at the #VSSML18 on September 13-14 in #Valencia Register today! bigml.com/events/valenci… #MachineLearning for everyone! This event is co-organized by #BigML and @VITEmprende

Checkout this article to understand the significance of harnessing online product reviews with the help of #TopicModeling. Prateek Joshi demonstrates the application of LDA on a raw, crowd-generated #textdata. buff.ly/2GIkUS4


Great talk on Project Feels @nytimes by @AlexanderSpangh at #ODSC labeling #textdata with #crowdsourcing for emotions. #Datascience




📍 TextData simplifies exploratory data analysis of text data and saves a significant amount of coding time: hubs.la/Q018H8-t0 #DataAnalysis #TextData

Tokenization is a concept you must know if you want to work with #TextData. Here, Aravind Pai discusses the various nuances of tokenization, including how to handle Out-of-Vocabulary words (OOV)! #NLP buff.ly/2KnwSnN


How to clean Text Data without manual Data manipulation Decoding by @eelrekab 👉 ow.ly/sVgK30nvEyd #data #bigdata #textdata


Working through committee, reviewer comments to our @sesync #gradpursuits proposal (loosely) on #sentiment about environmental shocks as expressed through #textdata. What a great process/experience to work through. Love the careful, detailed, constructive feedback! #datamining


Our #Wendesdaymorning breakfast sessions are ready to go. Today, we are providing expert insights into Descriptive and Predictive Analytics on #TextData using #bigdata and #AI

Pre-processing #textdata remains as important as ever & is used in almost all applications that work with textual data. This #article provides a checklist & a guide to basic yet essential processing steps to achieve better results on #machinelearning model buff.ly/2rxwytf

Part-of-Speech Tag, Dependency, and Constituency Parsing are some of the most fundamental concepts of #NLP that enable us to extract information from unstructured #textdata. Here is an article by Abhishek where he explains these fundamental concepts of NLP buff.ly/37uJCkZ


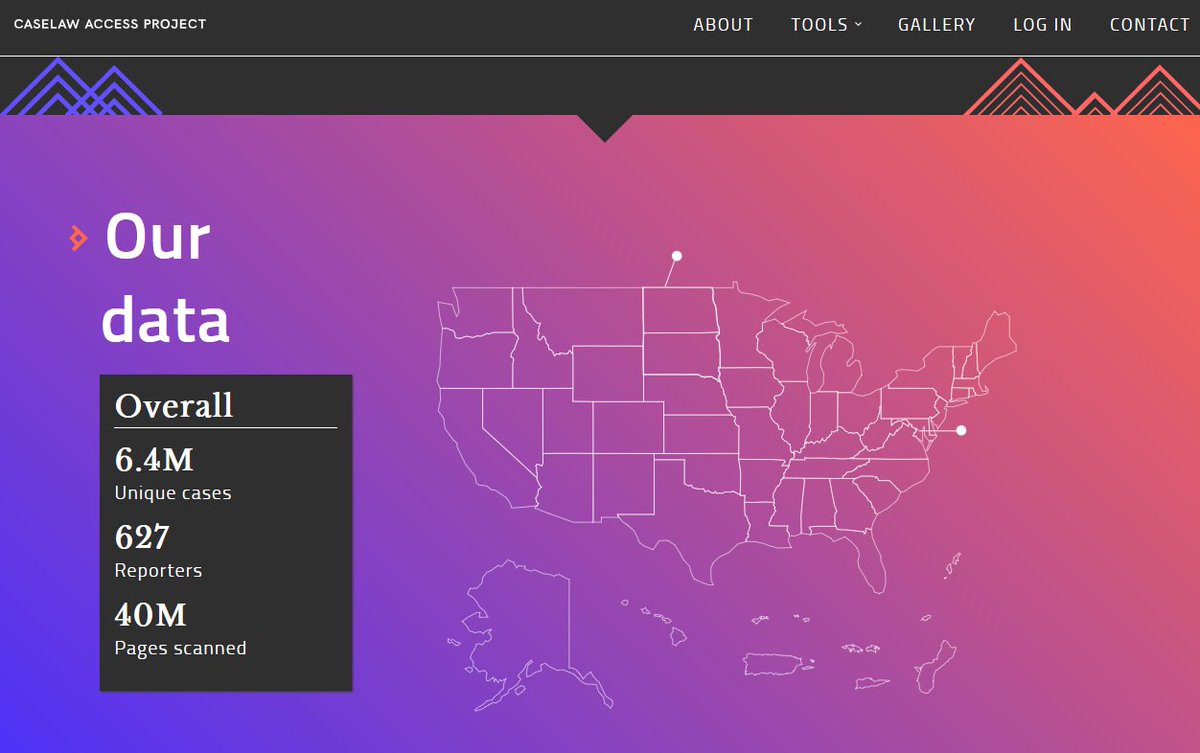
40M pages of court decisions contained in 40K bound volumes owned by the Harvard Law School Library are now freely available #textdata #AI #NLP #trainingdata case.law/about/#numbers

🔥 Read our Highly Cited Paper 📚 Research and Development of a Modern #DeepLearning Model for #EmotionalAnalysis Management of #TextData 🔗 mdpi.com/2076-3417/14/5… 👨🔬 Iryna Bashynska et al. 🏫 @AGH_Krakow / @onpu_opu #BERT #emotionsprediction…


AI language models use large amounts of text data to learn patterns and predict the next word in a sentence. They use algorithms to generate human-like text responses based on the input they receive. #AILanguageModels #TextData #Algorithms


soon_svm’s ability to handle text data with appropriate kernels is a game - changer. Process text efficiently! 📚 #soon_svm #TextData. @soon_svm #SOONISTHEREDPILL

La donnée c'est aussi ce que nous écrivons sur les réseaux. #Data #TextData #Sémantique

📹 Ready for Chapter 2? 📹 Check out the video below for a sneak peek inside chapter 2 of Build a Large Language Model (From Scratch) by @rasbt: mng.bz/1XyX #LLMs #TextData #AI

Following our recent update for Lithuanian, we’re introducing the new Lithuanian Web corpus 2021! It's lemmatized, part-of-speech tagged, and classified by genres and topics. #corpuslinguistics #digitalhumanities #textdata sketchengine.eu/lttenten-lithu…

As AI continues transforming industries, one key factor is driving innovation. More here: eu1.hubs.ly/H0d9dhl0 #AI #NaturalLanguageProcessing #TextData #AIinBusiness #Statzon

🚀 #ecprms online course 💻 Quantitative Text Analysis and Machine Learning using R @zacdgreene 🔍 Learn to effortlessly manage & analyse #textdata with #R 📆 24–28 March 2025 🛎️ Limited spots, secure your space now! ecpr.eu/Events/Event/P…
🚀 #ecprms online course 💻 Quantitative Text Analysis and Machine Learning using #R @zacdgreene 🔍 Learn to effortlessly manage & analyse #textdata with R ecpr.eu/Events/Event/P… 📆 24–28 Mar 🐦 Early Bird rates until 31 Oct with #ECPRMemberPerks

Estudia el procesamiento de lenguaje natural (NLP) para trabajar con datos textuales. Técnicas como tokenización y análisis de sentimiento son fundamentales. #NLP #TextData

#SUERFpolicybrief “Through Rose-Tinted or Dark Lenses: How Bank Manager Sentiment Affects Lending and Risk” by Frank Brückbauer (@zew_en Mannheim) and Thibault Cézanne (@EconUniMannheim, ZEW Mannheim) ➡️tinyurl.com/4adff864 #TextData #Extrapolation #LoanGrowth #SystemicRisk


Exciting news from FineWeb - they're revolutionizing text data collection on a large scale, making it easier to access high-quality information from the web. #FineWeb #TextData #Innovation ift.tt/j546ZFq






5 NLP libraries for working with Text data ! #nlp #libraries #textdata #genism #textblob #spacy #corenlp #python #data #datascience #machinelearning #ai #deeplearning #analytics #dataanalytics #bitscrunch P.S - DatumGuy
Introducing the fresh Assamese Corpus on Sketch Engine! Dive into 2.5 million words of Assamese (Asamiya), an Indo-Aryan language spoken in Assam, India. It's cleaned, deduplicated, and ready for your linguistic exploration. #textdata #LanguageAnalysis sketchengine.eu/assamese-corpu…

If you have #TextData but haven't gotten around learning how to analyze them, this Medium article can help get you started by breaking through the computer science jargon. You might already know more #TextAnalytics than you think! link.medium.com/sVvk7oWFshb
How to clean Text Data without manual Data manipulation Decoding by @eelrekab 👉 ow.ly/sVgK30nvEyd #data #bigdata #textdata
I decided to convert our paper on #textdata and #twitter into a poster using #rstats package #posterdown @hdcripps @mejtoft @rforresearch. Have a read of the full paper which is #openaccess as this infographics only shows #textmining results. Thx @wbrentthorne for the package!

What are the different sources for #textdata?@npendar, #NLP #DataScience @skytreeHQ @Dataversity #machinelearning

Loving @maxharlow's csvmatch session at #nicar18 - Fuzzy matching made easy for journalists #ddj #textdata



#100Daysofmlcode Checkout this article to understand the significance of harnessing online product reviews with the help of #TopicModeling. Prateek Joshi demonstrates the application of LDA on a raw, crowd-generated #textdata bit.ly/2H1P4yV



#textmining #DataAnalytics #textdata #npl @aksingh1985 great presentation now I know what we are doing with our research data @EdithCowan
Interested in #textdata visualization? Check out my collection of examples on @Pinterest and follow my boards to see what's new pinterest.com/barbara_maseda #DataVisualization #dataviz #textviz


What can we learn about The #WalkingDead by analyzing #textdata?j.mp/2NthemS #textanalytics #textexploration #textanalysis #jmp

Learn how to find thematically related terms in your #TextData with #TopicModels at the #VSSML18 on September 13-14 in #Valencia Register today! bigml.com/events/valenci… #MachineLearning for everyone! This event is co-organized by #BigML and @VITEmprende
Following our recent update for Lithuanian, we’re introducing the new Lithuanian Web corpus 2021! It's lemmatized, part-of-speech tagged, and classified by genres and topics. #corpuslinguistics #digitalhumanities #textdata sketchengine.eu/lttenten-lithu…

Julia Silge from @StackOverflow - PhD in astrophysics - speaking about building effective #textdata tools: Count-based methods #R #textmining #TextXD17 • Online book: tidytextmining.com

📍 TextData simplifies exploratory data analysis of text data and saves a significant amount of coding time: hubs.la/Q018H8-t0 #DataAnalysis #TextData

Processing #TextData just got easier with @MATLAB . Explore and Download the latest release today! #R2017b - mathworks.com/products/new_p…





Something went wrong.
Something went wrong.
United States Trends
- 1. Cowboys 61.6K posts
- 2. Cowboys 61.6K posts
- 3. LeBron 82.6K posts
- 4. Gibbs 14.2K posts
- 5. Brandon Aubrey 6,248 posts
- 6. Ferguson 9,687 posts
- 7. #OnePride 8,004 posts
- 8. #DALvsDET 5,535 posts
- 9. Bland 7,915 posts
- 10. Goff 7,665 posts
- 11. CeeDee 9,248 posts
- 12. Pickens 10.8K posts
- 13. Eberflus 1,189 posts
- 14. Shang Tsung 14.6K posts
- 15. Austin Reaves 12K posts
- 16. #LakeShow 3,761 posts
- 17. Schotty 1,434 posts
- 18. Al Michaels N/A
- 19. Turpin 1,873 posts
- 20. Sixers 12K posts