#variationalgraphautoencoder arama sonuçları

These 94 lines of code are everything that is needed to train a neural network. Everything else is just efficiency. This is my earlier project Micrograd. It implements a scalar-valued auto-grad engine. You start with some numbers at the leafs (usually the input data and the…


we can go beyond attention. as some of you know, higher-order attention methods (and the resulting schizodrawings) have been my focus for a while now, and, despite my earlier plans, they ended up being my choice for the second post in the series titled "the graph side of…


Efficient training of neural networks is difficult. Our second Connectionism post introduces Modular Manifolds, a theoretical step toward more stable and performant training by co-designing neural net optimizers with manifold constraints on weight matrices.…


ChatGPT is so advanced now. I needed to find the differential nonlinear error of this DAC board i designed and was using a nanovoltmeter. stepping though DAC codes up to 10V lowers the # of digits you can see on the voltmeter so i was stumped on how i could see a reading << 1 DAC…


Biweekly update: PRODUCT ➡️ The most recent mainnet release was v0.2.3. ➡️ Spreads have been tightened across the board (e.g. BTC spreads for small orders have been cut by 90%+). ➡️ Updated spread display to show more precision (especially on tighter spreads). ➡️ Tweaks to loss…


three years ago, DiT replaced the legacy unet with a transformer-based denoising backbone. we knew the bulky VAEs would be the next to go -- we just waited until we could do it right. today, we introduce Representation Autoencoders (RAE). >> Retire VAEs. Use RAEs. 👇(1/n)


刚刚翻出了这张图来纪念下 @virtuals_io 看到这张图我敢打赌国人95%会感到非常陌生 去年带着徒弟们披荆斩棘 20万市值买过 $AIXBT 3.5万市值买到过 $VADER 0.15的 $VIRTUALS 甚至许多低市值的 去年Aiagent确实吃饱了 发这些并不想证明什么只想说现在的预测市场跟去年的Aiagents 真的还处于空白的档期

Diffusion Transformers with Representation Autoencoders "Most DiTs continue to rely on the original VAE encoder" "In this work, we explore replacing the VAE with pretrained representation encoders (e.g., DINO, SigLIP, MAE) paired with trained decoders, forming what we term…


VA-GS: Enhancing the Geometric Representation of Gaussian Splatting via View Alignment Qing Li, Huifang Feng, Xun Gong, @Yushen_thu tl;dr: edge-aware image cues+visibility-aware photometric alignment loss+normal-based constraints+deep image feature embeddings…




diffusion transformers have come a long way, but most still lean on the old 2021 sd-vae for their latent space. that causes a few big issues: 1. outdated backbones make the architecture more complex than it needs to be. the sd-vae runs at around 450 gflops, while a simple ViT-B…


Autoencoder that forces the latent factors to be independent, disentangled from each other. Discriminator makes this GAN-like; it tries to search for statistical dependence in the latent space

#SpatialTranscriptomics #BatchCorrelation SpaBatch Align multi-slice sequencing-based spatial data Visium ST Stereo-seq #VariationalGraphAutoEncoder Masked data augmentation vs STG3Net STAligner SEDR DeepST SpaGIC STitch3D bioRxiv 2025 biorxiv.org/content/10.110…


I was curious about how Stein variational gradient descent (SVGD; Liu & Wang, 2016) behaves in the presence of multiple modes. Seems quite robust and sensible (made with #python #jax #numpy @matplotlib)

I spent some time last summer thinking about discrete optimization (e.g. MoEs, VQ-VAE) w/ @LiyuanLucas. A simple test bed for this is a Variational Autoencoder where the latent space is a categorical distribution (not Gaussian). Since I couldn’t find many resources on this…


SORA by Hand ✍️ OpenAI’s #SORA took over the Internet when it was announced earlier this year. The technology behind Sora is the Diffusion Transformer (DiT) developed by William Peebles and Shining Xie. How does DiT work? 𝗚𝗼𝗮𝗹: Generate a video conditioned by a text prompt…

Vibe Coding still needs Application Security (AppSec). Yes, Vibe Coding Security is a thing… #VibeCoding #AppSec #AI #CyberSecurity


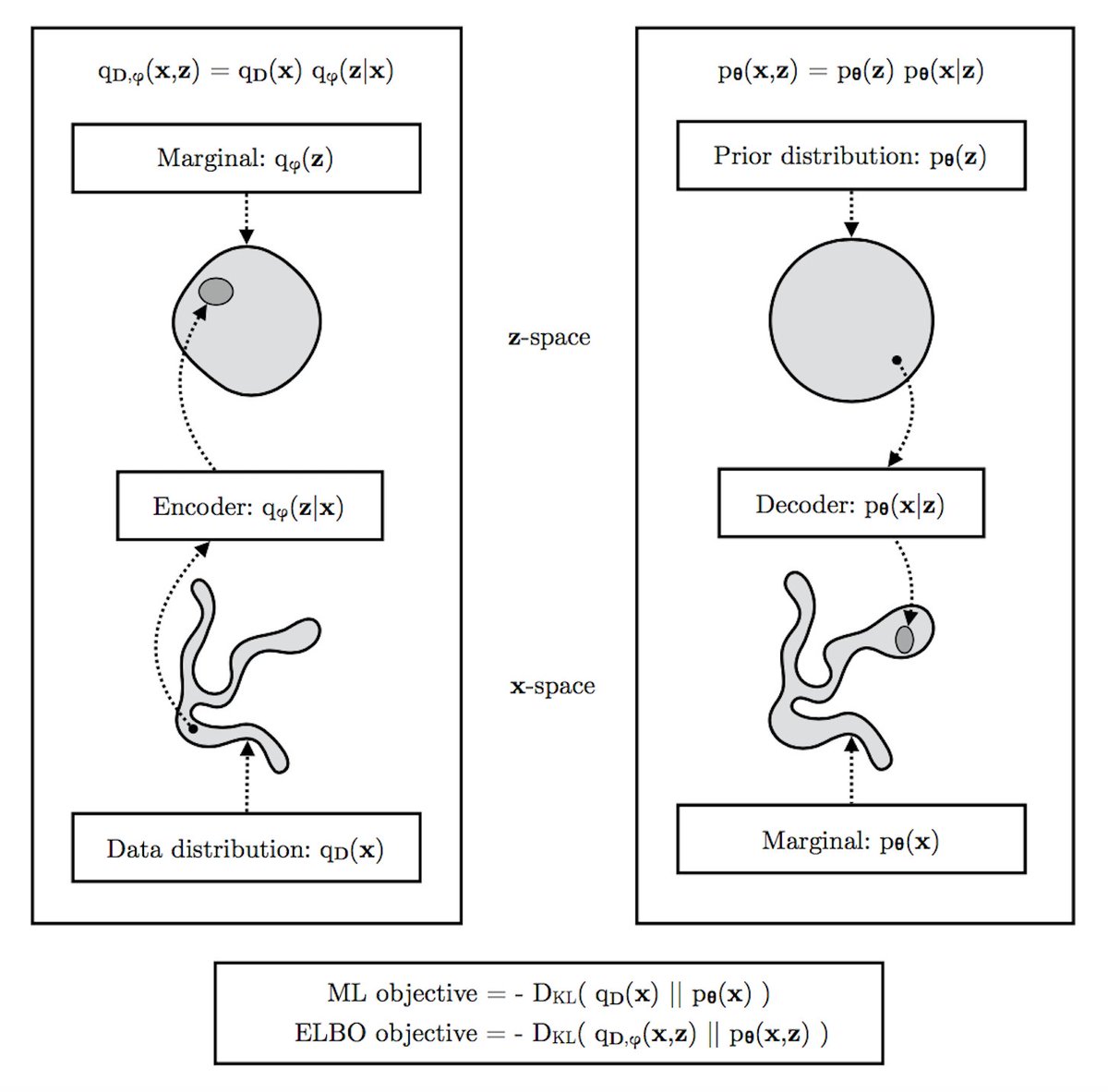
A figure I made for explaining variational autoencoders (VAEs) as part of a larger work-in-progress.

Per-weight dropout! Variational Dropout Sparsifies Deep Neural Networks paper: arxiv.org/abs/1701.05369 github: github.com/ars-ashuha/var…


actually, in-context learning sort of "implicitly" learns via grad-descent. for reference, this paper (arxiv.org/pdf/2507.16003) states that each "token" in the context vector acts as a data point and updating weight is equivalent to “weight update = previous weight − h ×…


Dwarkesh @ 15:16: "but the in-context learning itself is not gradient descent" orly?


Diffusion Transformers with Representation Autoencoders “In this work, we explore replacing the VAE with pretrained representation encoders (e.g., DINO, SigLIP, MAE) paired with trained decoders, forming what we term Representation Autoencoders (RAEs).”

#SpatialTranscriptomics #BatchCorrelation SpaBatch Align multi-slice sequencing-based spatial data Visium ST Stereo-seq #VariationalGraphAutoEncoder Masked data augmentation vs STG3Net STAligner SEDR DeepST SpaGIC STitch3D bioRxiv 2025 biorxiv.org/content/10.110…
#SpatialTranscriptomics #BatchCorrelation SpaBatch Align multi-slice sequencing-based spatial data Visium ST Stereo-seq #VariationalGraphAutoEncoder Masked data augmentation vs STG3Net STAligner SEDR DeepST SpaGIC STitch3D bioRxiv 2025 biorxiv.org/content/10.110…
Something went wrong.
Something went wrong.
United States Trends
- 1. Prince Andrew 21.2K posts
- 2. Duke of York 10.6K posts
- 3. No Kings 264K posts
- 4. zendaya 8,627 posts
- 5. trisha paytas 3,477 posts
- 6. Zelensky 65.6K posts
- 7. Apple TV 7,036 posts
- 8. #FursuitFriday 16.4K posts
- 9. #DoritosF1 N/A
- 10. Andrea Bocelli 14.6K posts
- 11. Arc Raiders 6,639 posts
- 12. #CashAppFriday N/A
- 13. Karoline Leavitt 50.7K posts
- 14. TPOT 20 SPOILERS 8,450 posts
- 15. Strasbourg 17.1K posts
- 16. #FridayVibes 9,415 posts
- 17. My President 54.8K posts
- 18. F-bomb 1,629 posts
- 19. $NXXT 1,567 posts
- 20. Trevon Diggs 1,383 posts