
FireHacker
@thefirehacker
Founder-AI Researcher. Building BubblSpace & Timecapsule
Talvez você curta











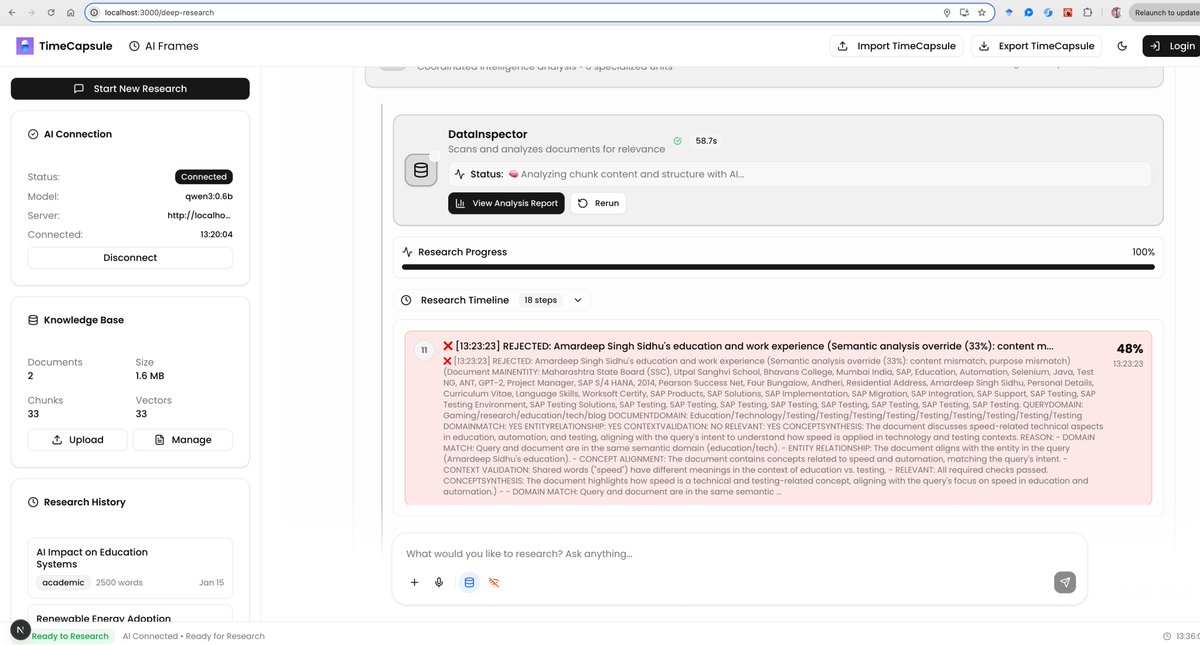
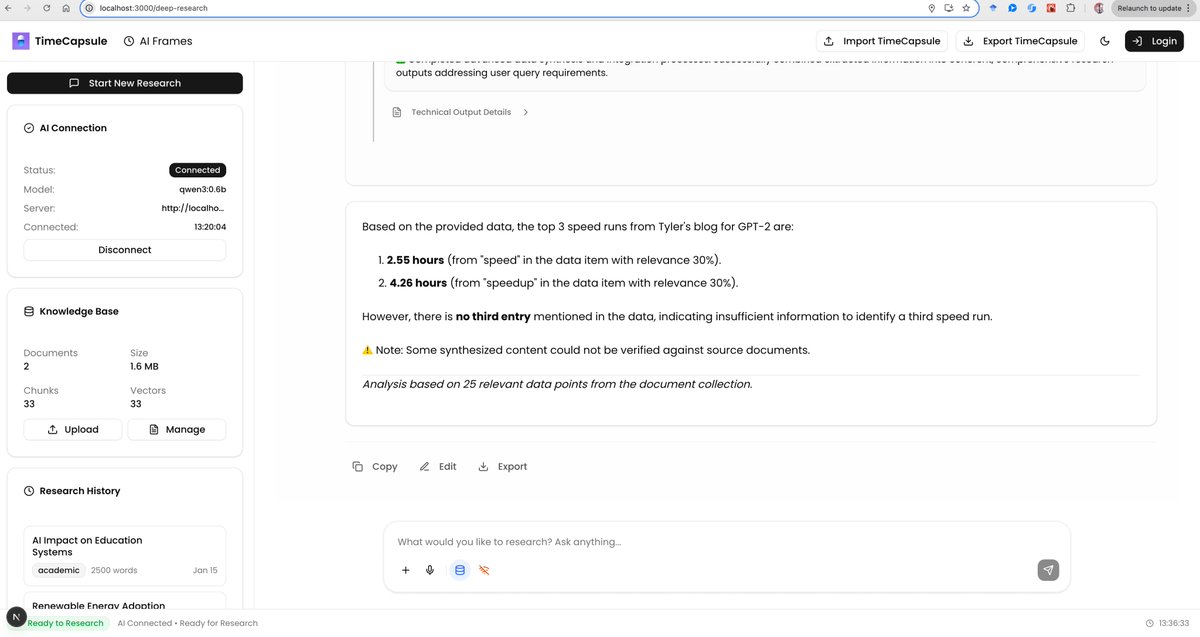
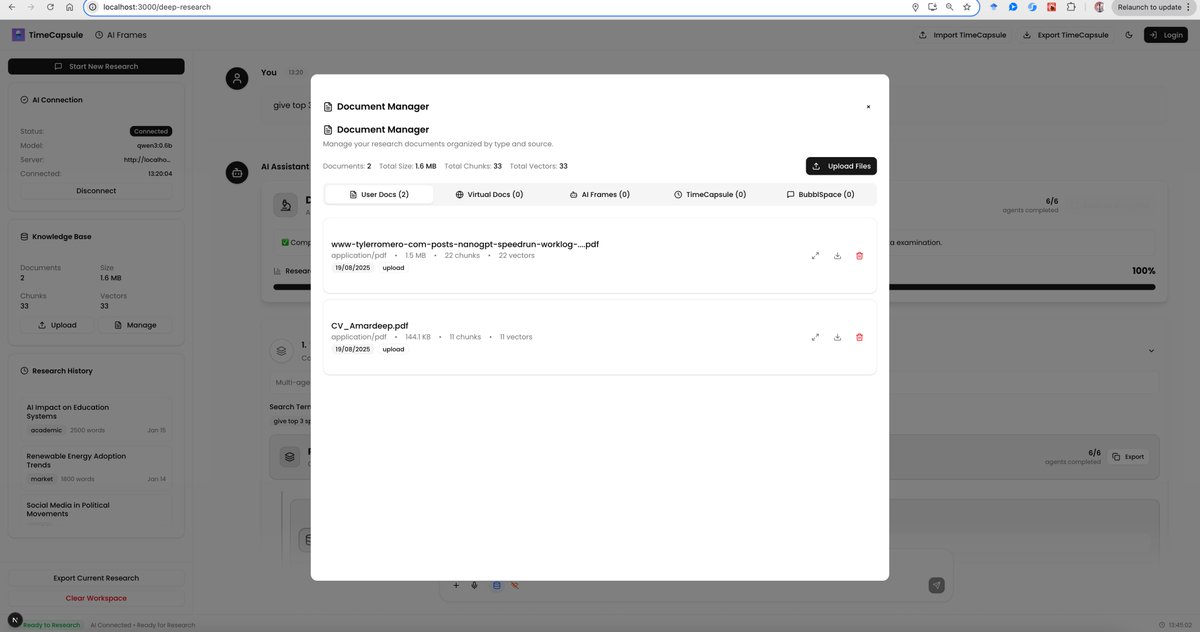
🔥1+ month of effort and first signs of success! Final Product: TimeCapsule-SLM An Open Source Deepresearch that works in browser with Qwen 3 0.6b(ollama) that has semantic understanding , provide insights & generate novel ideas . Privacy first local Deep Research. 👽…
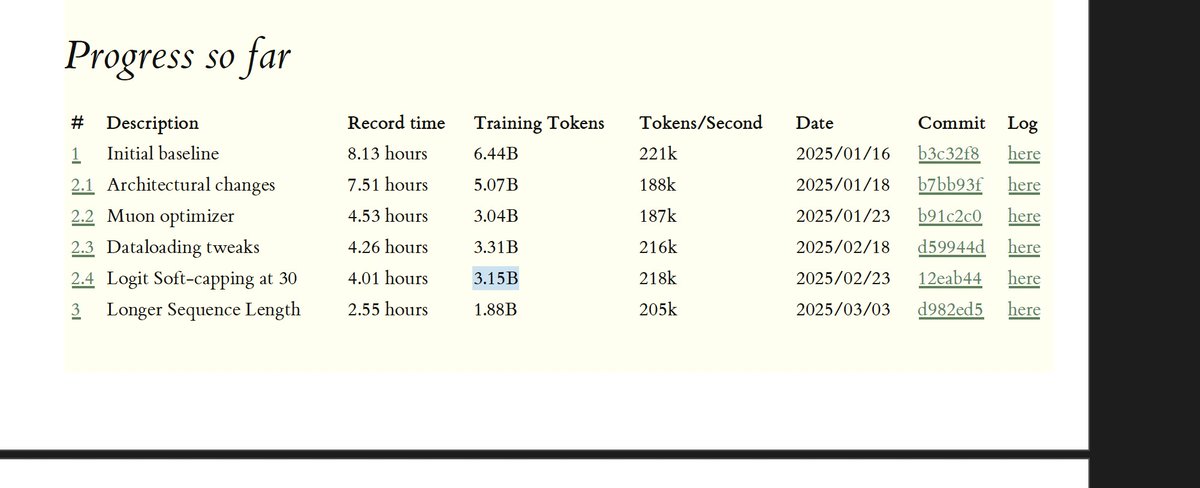

It's that time of the year again and we're coming with another @GPU_MODE competition! This time in collaboration with @nvidia focused on NVFP4. Focused on NVFP4 and B200 GPUs (thanks to @sestercegroup ) we'll release 4 problems over the following 3 months: 1. NVFP4 Batched GEMV…


A spectacular win by the Indian team in the ICC Women’s Cricket World Cup 2025 Finals. Their performance in the final was marked by great skill and confidence. The team showed exceptional teamwork and tenacity throughout the tournament. Congratulations to our players. This…

DY Patil crowd cheering up Laura Wolvaardt for her heroics. 👏


India 🇮🇳 wins the Women's World Cup 2025 🎉


A photographer in southern Spain captured what is believed to be the first-ever white Iberian lynx, a leucistic big cat so rare it seems almost mythical. Already one of the world’s rarest cats, the Iberian lynx was pulled back from the brink of extinction after its population…

🎉 Congrats to @Kimi_Moonshot! vLLM Day-0 model expands! Now supporting Kimi Linear — hybrid linear attention with Kimi Delta Attention(KDA): - RULER 128k context: 84.3 perf + 3.98× speedup - Up to 6× faster decoding & 6.3× faster TPOT (1M tokens) - 75% KV cache reduction 💡…


Kimi Linear Tech Report is dropped! 🚀 huggingface.co/moonshotai/Kim… Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi…


Well, training and inference have converged due to the reasoning paradigm When an inference data center has low utilization (at night and weekends) It can be used for RL rollouts to generate training data

Thought this was important color too. Even a year ago, people assumed that it was either a training data center or inference as the infra looks different. Increasingly, the hyperscalers are building with flexibility & modernization in mind. Satya on the MSFT call: "One is how…

Kimi Linear Tech Report is dropped! 🚀 huggingface.co/moonshotai/Kim… Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi…
The greatest scorecard in the history of cricket 🏏 As this is the most successful run-chase in the history of icc knockout match (men's and women's both) India 🇮🇳 beat the invincible Australian women's 🔥

Jemimah Rodrigues in tears after receiving player of the match award 👏🏻



#Final, 𝗛𝗘𝗥𝗘 𝗪𝗘 𝗖𝗢𝗠𝗘! 🇮🇳 #TeamIndia book their spot in the #CWC25 final on a historic Navi Mumbai night! 🥳👏 Scorecard ▶ bit.ly/INDWvAUSW-2nd-… #WomenInBlue | #INDvAUS


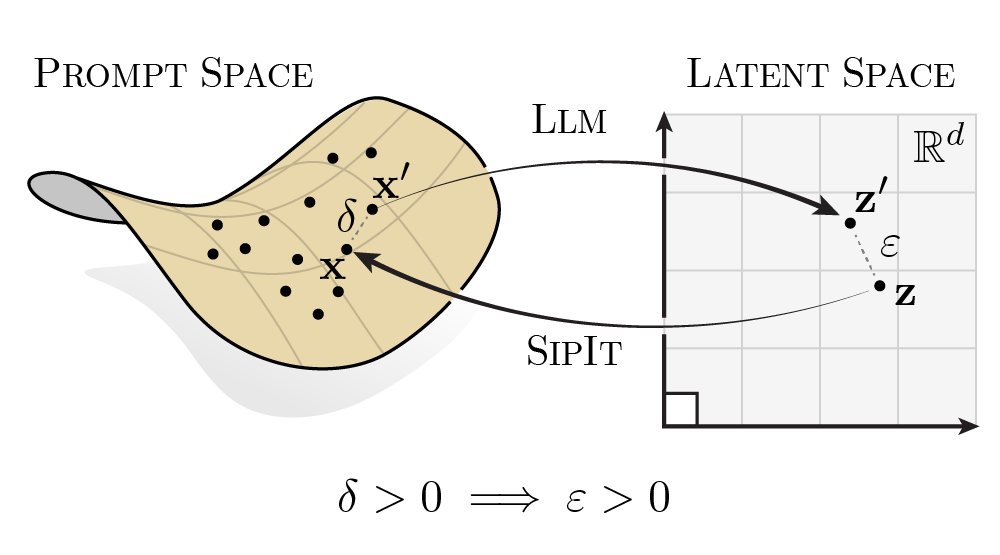
LLMs are injective and invertible. In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space. (1/6)

One year at OpenAI today ... It has been quite a ride, even more exciting than I expected! I joined as GPT-4.5 was being prepared, got some minor action on o3, and dove deeper for GPT-5. Being a spectator to the multi-modal releases (sora-1, imagegen, sora-2) was also absolutely…

Multi-splat object LOD test in sparkjs. 7 AI generated worlds, 12.5m total splats. Pretty consistent 120 fps on my laptop.

Adaptable Intelligence. Multiple possible paths to an objective.

$META call is live. Zuck says he will overbuild for the most optimistic case around Superintelligence. That means they will likely spend at a rate faster than Google, Microsoft and Amazon. That’s also how the Street is modeling our Capex for those companies with Meta up…

I'd put good money on this being an high-impact finetune of one of the large, Chinese MoE models. I'm very excited to see more companies able to train models that suit their needs. Bodes very well for the ecosystem that specific data is stronger than a bigger, general model.

Introducing Cursor 2.0. Our first coding model and the best way to code with agents.

Just submitted my resignation from Meta. Some might say that ~one year at the company is not that long, but I survived like three rounds of layoffs, so I think it’s fair play. For what it's worth, my team is great and it was an overall positive experience. But there are other,…

the best thing to drop this entire month. this information is useful in a myriad of ways.
LLMs are injective and invertible. In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space. (1/6)


























































































United States Tendências
- 1. Godzilla 25.8K posts
- 2. Trench 7,706 posts
- 3. Shabbat 3,424 posts
- 4. $DUOL 2,804 posts
- 5. #Unrivaled N/A
- 6. Barca 99.8K posts
- 7. Brujas 29.6K posts
- 8. #dispatch 41.6K posts
- 9. Lamine 68.6K posts
- 10. Barcelona 157K posts
- 11. Toledo 10.5K posts
- 12. Brugge 50.6K posts
- 13. Captain Kangaroo N/A
- 14. Sharia 123K posts
- 15. Alastor 90.6K posts
- 16. Richardson 3,496 posts
- 17. Phee N/A
- 18. Flick 39.2K posts
- 19. Darius Garland 1,135 posts
- 20. Jared Golden 2,323 posts
Talvez você curta
-
 Ünver Çiftçi
Ünver Çiftçi
@scientficai -
 Sabyasachi Sahoo
Sabyasachi Sahoo
@saby_tweets -
 Anuj Dutt
Anuj Dutt
@anujdutt92 -
 BubblSpace
BubblSpace
@bubblspace -
 Sourav M
Sourav M
@souravmohanty07 -
 Dinorego 🇿🇦
Dinorego 🇿🇦
@mphogo_dinorego -
 Dr S. Sagar Srinivas
Dr S. Sagar Srinivas
@SagarSrinivasS1 -
 Spurthi Amba Hombaiah
Spurthi Amba Hombaiah
@spurthi_ah -
 AIEdX
AIEdX
@AIEdXLearn -
 Fayez
Fayez
@aldoghanfayez23 -
 Sergio Sánchez S
Sergio Sánchez S
@sergio_sstban
Something went wrong.
Something went wrong.