
你可能會喜歡











Use your favourite AI coding agent to create AI frames. What if you could connect everything—your PDFs, videos, notes, code, and research—into one seamless flow that actually makes sense? AI-Frames: Open Source Knowledge-to-Action Platform:timecapsule.bubblspace.com ✨ Annotate •…

On value functions, great answer. Michael Truell: Why aren't value functions popular in RL right now? John Schulman: I'd say they don't seem to help very much in the settings that people are doing RL on right now. So for example, doing RL from human feedback and RL on these…

A conversation with @johnschulman2 on the first year LLMs could have been useful, building research teams, and where RL goes from here. 00:20 - Speedrunning ChatGPT 09:22 - Archetypes of research managers 11:56 - Was OpenAI inspired by Bell Labs? 16:54 - The absence of value…

This is the Outstanding Paper Award at ICLR 2025, and this is exactly the kind of research on LLMs we need, not those quasi-psychological studies of the form "we asked the same question to these 3 models and see which one is more racist!" As you might already know, when…


We are thrilled to share significant progress on our ambitious Artificial Intelligence (AI) and Large Language Model (LLM) development program for Sanskrit, which was officially inaugurated on Vijayadasami day this year. The Core Mission and Team A dedicated core group of…


VIDEO FOR THE AGES - SACHIN TENDULKAR AND LEO MESSI ON THE SAME STAGE. ❤️

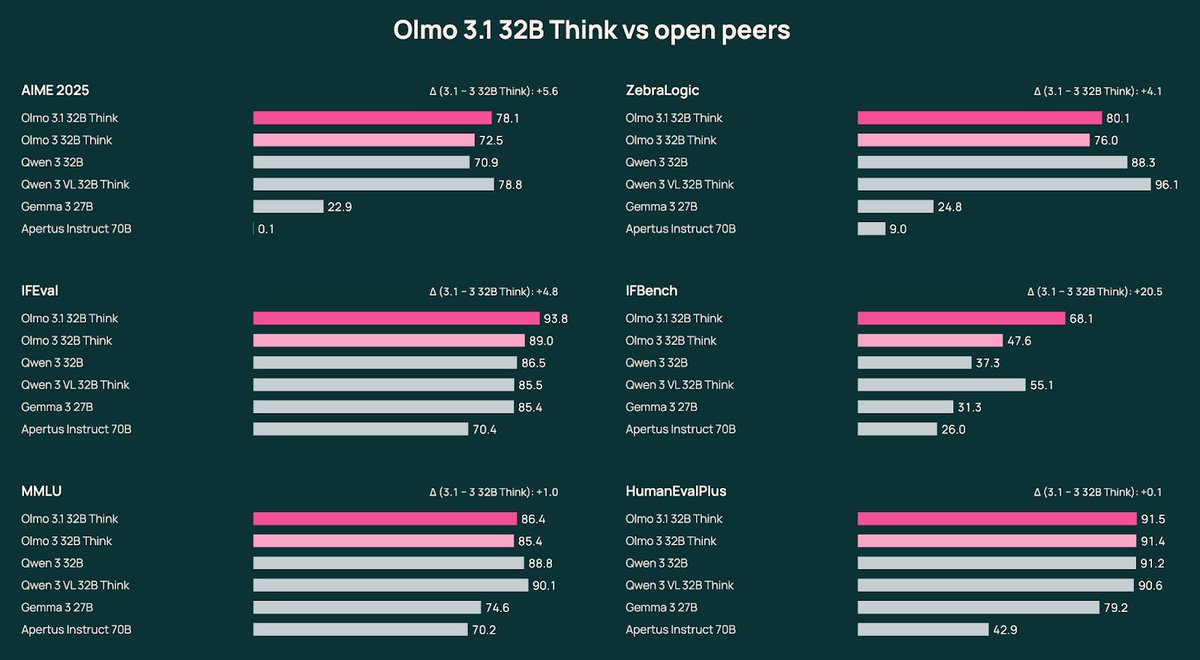
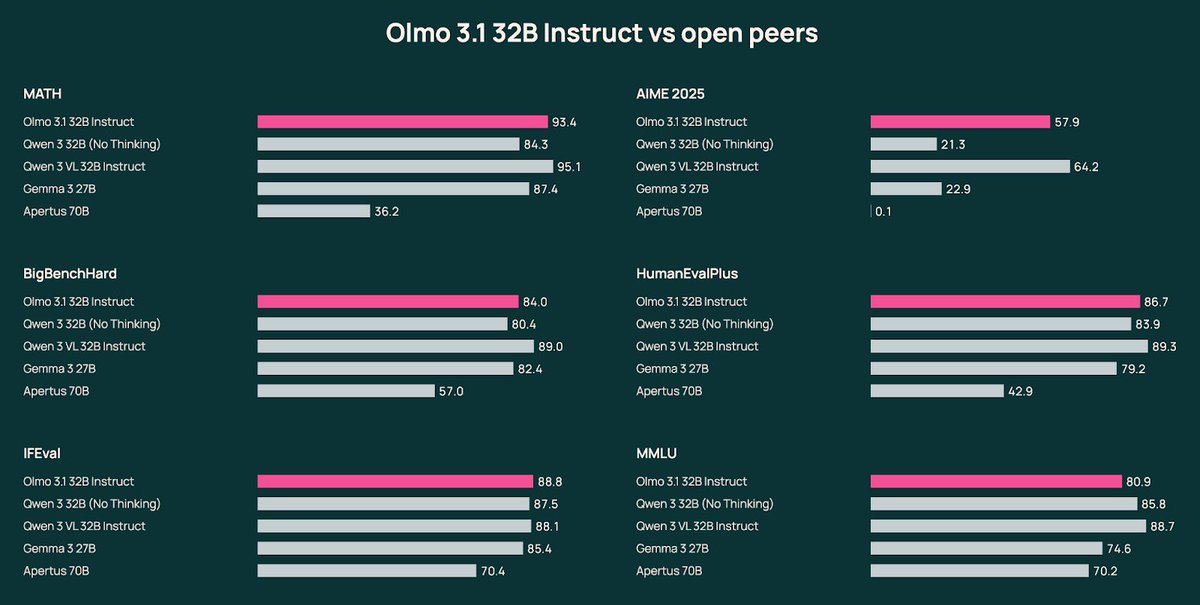
Olmo 3.1 is here. We extended our strongest RL run and scaled our instruct recipe to 32B—releasing Olmo 3.1 Think 32B & Olmo 3.1 Instruct 32B, our most capable models yet. 🧵

Today we open source Nomos 1. At just 30B parameters, it scores 87/120 on this year’s Putnam, one of the world’s most prestigious math competitions. This score would rank #2/3988 in 2024 and marks our first step with @hillclimbai towards creating a SOTA AI mathematician.




We need more senior researchers camping out at their posters like this. Managed to catch 10 minutes of Alyosha turning @anand_bhattad’s poster into a pop-up mini lecture. Extra spark after he spotted @jathushan. Other folks in the audience: @HaoLi81 @konpatp @GurushaJuneja.



Why does NVIDIA spend millions of GPU hours training models just to give it all away? Here's a recording to the talk at NeurIPS for anyone who couldn't make it, wish we recorded the questions afterwards!
I'm at NeurIPS! Giving a talk today on state of OSS & why NVIDIA spends millions of GPU hours training models just to give it all away: datasets, recipes, weights, architecture. 545pm @ Exhibit Hall A,B


This morning at NeurIPS, Rich Sutton reminded us that we need continual learning to reach AGI. This afternoon, Ali Behrouz presented a Google poster paper, Nested Learning, which provides new ideas on the path to continual learning. I recorded the 40 minute talk as it might be…

The NeurIPS Test of Time Award recognizes papers that have made lasting contributions to machine learning. For 2025 the award goes to…(buff.ly/W4ohNLA) #NeurIPS2025 #NeurIPSanDiego"



Now to wait for someone to have the best OSS UI for me to run Qwen3 Omni now that vLLM-Omni exists 😍


Holy sh*t. 🚨Running a Qwen3 fine-tune locally can compromise your entire system. Let's talk about a critical security vulnerability 🧵
As someone who has been crafting AI-Persona applications for the past two years, this felt like a pleasant surprise.I found this gold nugget on the Mexico City track !!! 🔥"First Workshop on LLM Persona Modeling" full day track at NeurIPS2025.Workshop. Workshop…

Same for me. I switched 100% to Gemini after 2.5pro. Similar quality as other models (certainly good enough for everyday tasks) but fantastically low latency.

I started using gemini 3 for anything that isn't a hardcore proof. Eg explaining concepts or well known things that don't require any new ideas. Much stabler and faster than 5.1 pro. At least I know it will finish and reply in 5 min and probably faster. With gpt 5.1 pro/thinking…

had some discussions that sparked a long thinking session so here is the yield. hope some of you enjoy consuming it.

On the streets of San Francisco, I met this really cool researcher going to NeurIPS from @smallest_AI who is working on the intersection between speech models and gravitational lensing! Link to the paper below!


























































































United States 趨勢
- 1. Nicki Minaj 46K posts
- 2. Bucs 6,254 posts
- 3. Bryce Young 2,401 posts
- 4. James Cook 4,839 posts
- 5. Judkins 5,613 posts
- 6. Chase Brown 1,837 posts
- 7. JJ McCarthy 2,501 posts
- 8. #KeepPounding 2,328 posts
- 9. #Browns 3,382 posts
- 10. Ewers 4,422 posts
- 11. #BillsMafia 6,373 posts
- 12. Jaxson Dart 2,049 posts
- 13. Abdul Carter N/A
- 14. #Skol 1,734 posts
- 15. #DawgPound 2,331 posts
- 16. Titans 13.7K posts
- 17. Sean Tucker N/A
- 18. Theo Johnson N/A
- 19. Brian Burns N/A
- 20. Mike Evans 2,505 posts
你可能會喜歡
-
 Ünver Çiftçi
Ünver Çiftçi
@scientficai -
 Sabyasachi Sahoo
Sabyasachi Sahoo
@saby_tweets -
 Anuj Dutt
Anuj Dutt
@anujdutt92 -
 BubblSpace
BubblSpace
@bubblspace -
 Sandeep Banerjee
Sandeep Banerjee
@_ml_fanatic -
 Dinorego 🇿🇦
Dinorego 🇿🇦
@mphogo_dinorego -
 Dr S. Sagar Srinivas
Dr S. Sagar Srinivas
@SagarSrinivasS1 -
 Spurthi Amba Hombaiah
Spurthi Amba Hombaiah
@spurthi_ah -
 AIEdX
AIEdX
@AIEdXLearn -
 Fayez
Fayez
@aldoghanfayez23 -
 Atena G. Mohammadi
Atena G. Mohammadi
@AtenaGMohammadi
Something went wrong.
Something went wrong.