
Bạn có thể thích















Excited to see TVM-FFI finally become a standalone module that can benefit many projects across the deep learning ecosystem! Seven years ago, I was working on @DGLGraph - a graph learning framework with multiple backend support (PyTorch, MXNet, TensorFlow) – alongside talented…

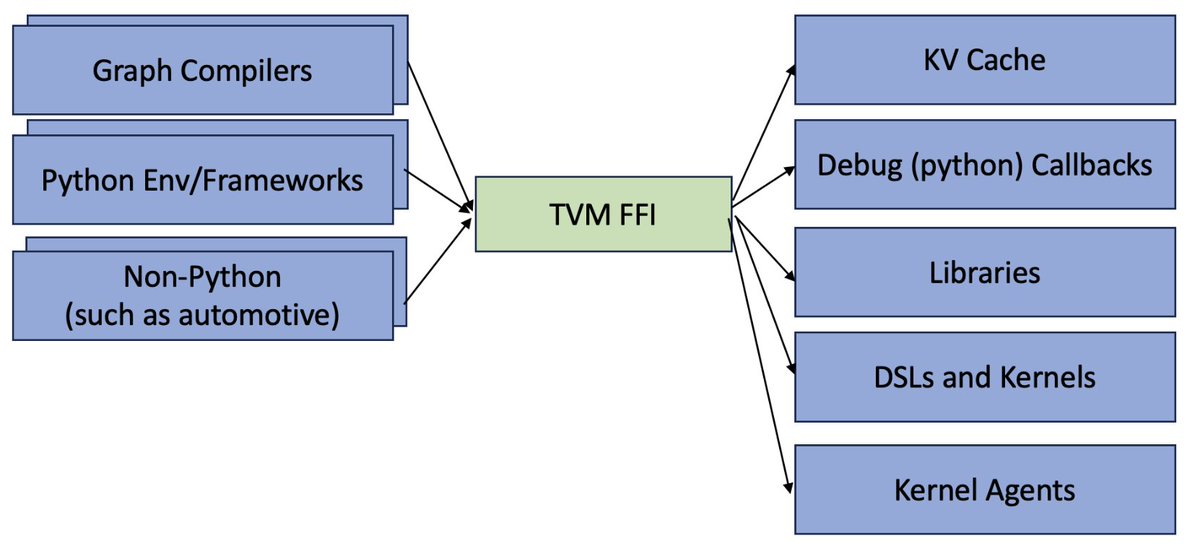
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…

On-policy + Reverse KLD = MiniLLM (arxiv.org/abs/2306.08543). Really nice blog by @thinkymachines. Exciting to see it being offered as a service!


Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

A small thread about how you should be drawing the contents of higher dimensional tensors


🤔 Can AI optimize the systems it runs on? 🚀 Introducing FlashInfer-Bench, a workflow that makes AI systems self-improving with agents: - Standardized signature for LLM serving kernels - Implement kernels with your preferred language - Benchmark them against real-world serving…



How to beat all compression using LLMs? ⚙️ Introducing LLMc — a lossless compressor built with LLMs. LLMc leverages the predictive power of LLMs to beat traditional compressors like Gzip and LZMA on natural language text. (1/4) 🔗 Blog Post: syfi.cs.washington.edu/blog/2025-10-0… 💻 Code:…

🚀 Follow-up to our last breakthrough on DeepSeek V3/R1 inference! On NVIDIA GB200 NVL72, SGLang now achieves 26k input tokens/s and 13k output tokens/s per GPU with FP8 attention + NVFP4 MoE - that’s a 3.8× / 4.8× speedup vs H100 settings. See the details in the 🧵 (1/4)


🚀 Introducing Sparse VideoGen2 (SVG2) — Pareto-frontier video generation acceleration with semantic-aware sparse attention! 🏆Spotlight paper accepted by #NeurIPS2025 ✅ Training-free & plug-and-play ✅ Up to 2.5× faster on HunyuanVideo, 1.9× faster on Wan 2.1 ✅ SOTA quality…
The main branch of sglang now supports deterministic inference with user-specified per-request seeds! It utilized kernels from @thinkymachines and introduced new optimizations & coverage. Run out of box for most hardware backends and pytorch versions.
SGLang now supports deterministic LLM inference! Building on @thinkymachines batch-invariant kernels, we integrated deterministic attention & sampling ops into a high-throughput engine - fully compatible with chunked prefill, CUDA graphs, radix cache, and non-greedy sampling. ✅…


Glad that you enjoyed it! To be precise, it's EP64 on the inference side, around 30GB per inference GPU. So it's around 30GB / 1.3s = 23 GB/s.


Excited to share what friends and I have been working on at @Standard_Kernel We've raised from General Catalyst (@generalcatalyst), Felicis (@felicis), and a group of exceptional angels. We have some great H100 BF16 kernels in pure CUDA+PTX, featuring: - Matmul 102%-105% perf…


At Thinking Machines, our work includes collaborating with the broader research community. Today we are excited to share that we are building a vLLM team at @thinkymachines to advance open-source vLLM and serve frontier models. If you are interested, please DM me or @barret_zoph!…
Awesome work from @thinkymachines and @cHHillee! The importance of determinism might be underestimated. Like with LLM-based compression (bellard.org/ts_zip/) - you really need things to work the same way whether you're doing prefill/decode or different batching setups. Here's…
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to…


This is the advantage of large nvlink domains or TPUs topology - the main reason to do PP is that you are bottlenecked on your DP comms and cannot scale TP further. But if you have high enough bandwidth across a large enough domain (like TPUs or NVL72), you don't need to do PP…
🚀 Presenting LiteASR: a method that halves the compute cost of speech encoders by 2x, leveraging low-rank approximation of activations. LiteASR is accepted to #EMNLP2025 (main) @emnlpmeeting


Sub-10-microsecond Haskell Sudoku solver implemented in hardware. unsafeperform.io/papers/2025-hs…

Tilelang now supports SM120 — give it a try if you have RTX 5090 🚀😎

🎉 Excited to share: We’ve open-sourced Triton-distributed MegaKernel! A fresh, powerful take on MegaKernel for LLMs—built entirely on our Triton-distributed framework. github.com/ByteDance-Seed… Why it’s awesome? 🧩 Super programmable ⚡ Blazing performance 📊 Rock-solid precision


One nice thing you can do with an interactive world model, look down and see your footwear ... and if the model understands what puddles are. Genie 3 creation.












































































































United States Xu hướng
- 1. Jayden Daniels 24.3K posts
- 2. Dan Quinn 6,957 posts
- 3. jungkook 600K posts
- 4. Perle Labs 5,006 posts
- 5. Jake LaRavia 5,659 posts
- 6. Seahawks 38.3K posts
- 7. Commanders 50.1K posts
- 8. Sam Darnold 15.1K posts
- 9. #RaiseHail 8,787 posts
- 10. 60 Minutes 74.4K posts
- 11. Bronny 14.8K posts
- 12. Marcus Smart 3,502 posts
- 13. Godzilla 42K posts
- 14. Joe Whitt 2,290 posts
- 15. #smilingfriends 5,974 posts
- 16. #BaddiesAfricaReunion 6,583 posts
- 17. #HHN34 1,100 posts
- 18. Jaxson Hayes 3,261 posts
- 19. Ware 5,210 posts
- 20. #RHOP 6,818 posts
Bạn có thể thích
-
 Lianmin Zheng
Lianmin Zheng
@lm_zheng -
 Zhuohan Li
Zhuohan Li
@zhuohan123 -
 ビクトリード
ビクトリード
@RealVictrid -
 Dacheng Li
Dacheng Li
@DachengLi177 -
 Ryan Hanrui Wang
Ryan Hanrui Wang
@hanrui_w -
 Sixian
Sixian
@noworkforsixian -
 Dr. Jian "dAIye" Weng
Dr. Jian "dAIye" Weng
@b1antaidaye -
 Junru Shao
Junru Shao
@junrushao -
 Ying Sheng
Ying Sheng
@ying11231 -
 Muyang Li
Muyang Li
@lmxyy1999 -
 Zhanghao Wu
Zhanghao Wu
@Michaelvll1 -
 Yihong Zhang
Yihong Zhang
@yihongz_bot -
 Jiawei Liu
Jiawei Liu
@JiaweiLiu_ -
 Jiaheng Zhang
Jiaheng Zhang
@jiahengzhang96 -
 Ligeng Zhu
Ligeng Zhu
@LigengZhu
Something went wrong.
Something went wrong.