#vllm search results


Docker Model Runner + @vllm_project - run safetensors models and scale to production without leaving your Docker workflow ⚡️ 🔗 Try it out: bit.ly/4psZN7z #Docker #vLLM #ModelRunner #AI #DevTools


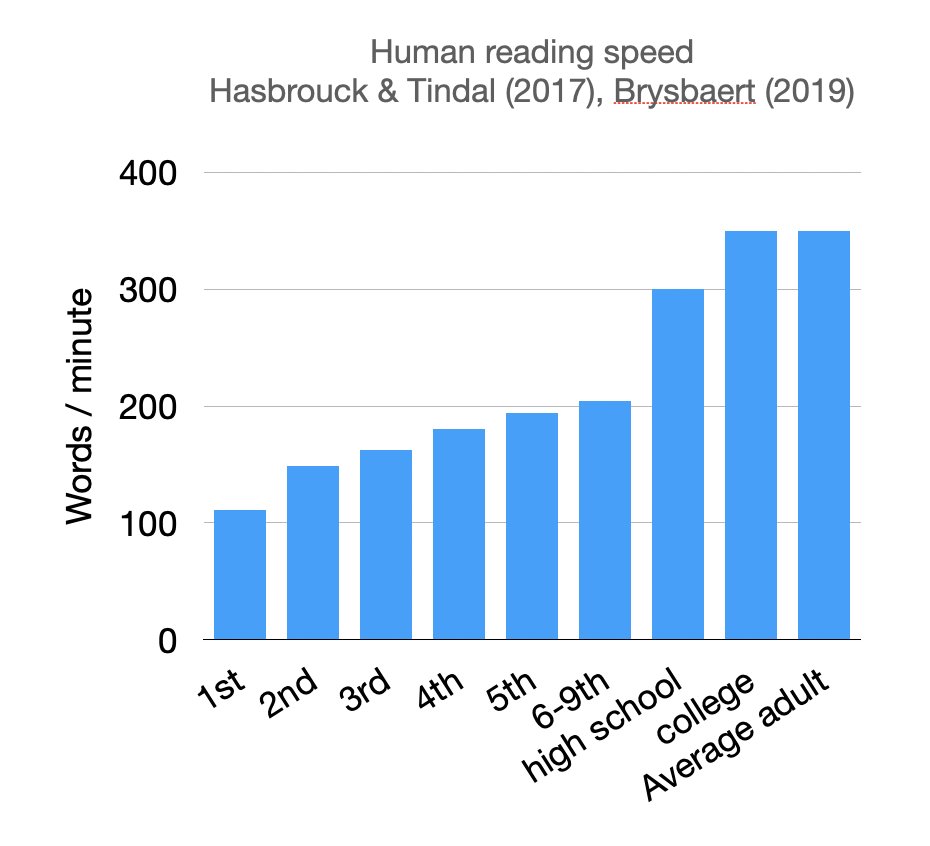
(1/n) We are drastically overestimating the cost of LLMs, because we sometimes over-focus for single-query speed. Had the privilege to talk about this topic at the #vllm meetup yesterday. An average human reads 350 words per minute, which translates to 5.5 words per second.

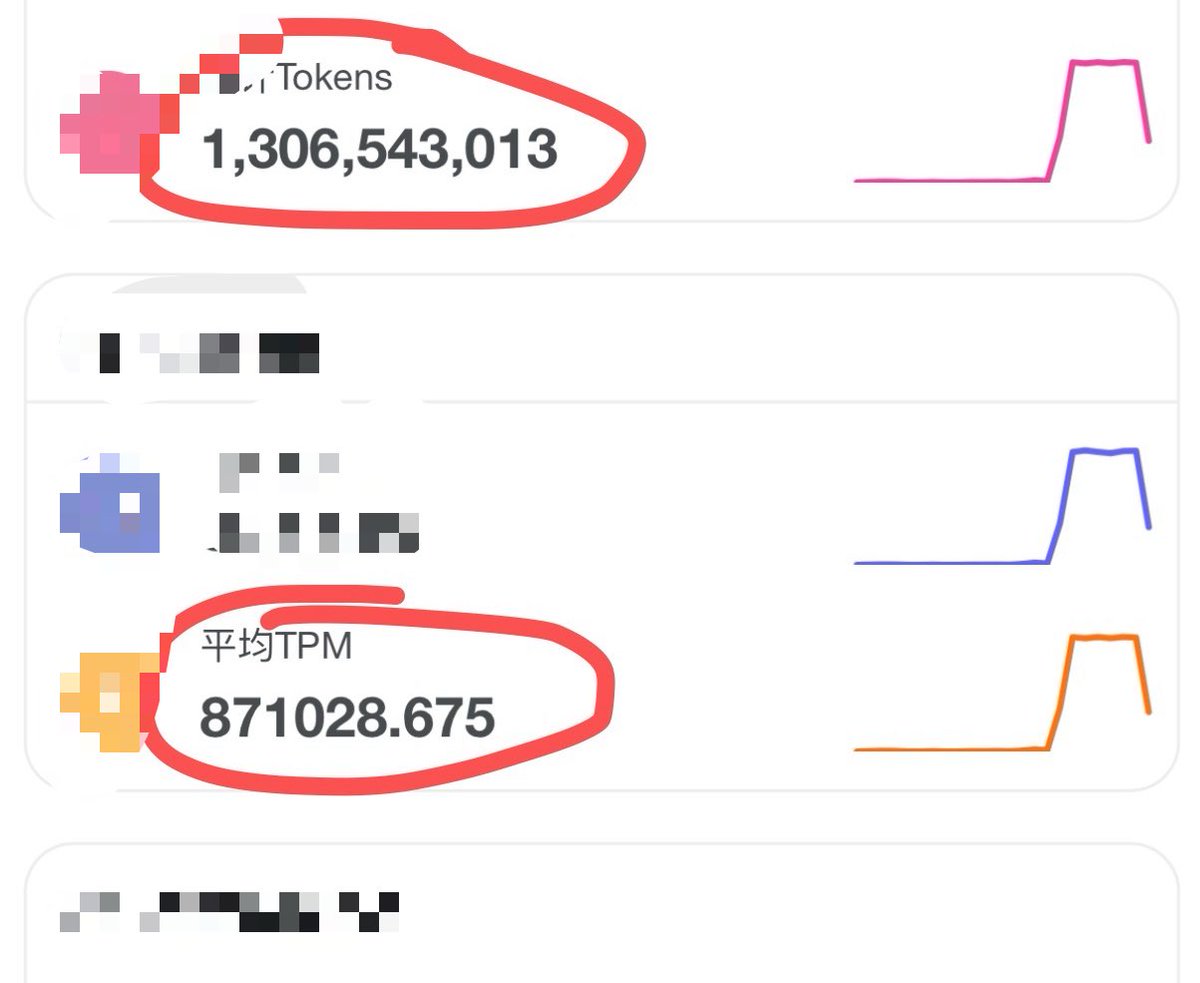
Thank you to everyone who filed issues, reviewed PRs, ran benchmarks, and helped shape this release. vLLM grows because the community does. Easy, fast, and cheap LLM serving for everyone. 🧡 #vLLM #AIInfra #OpenSource



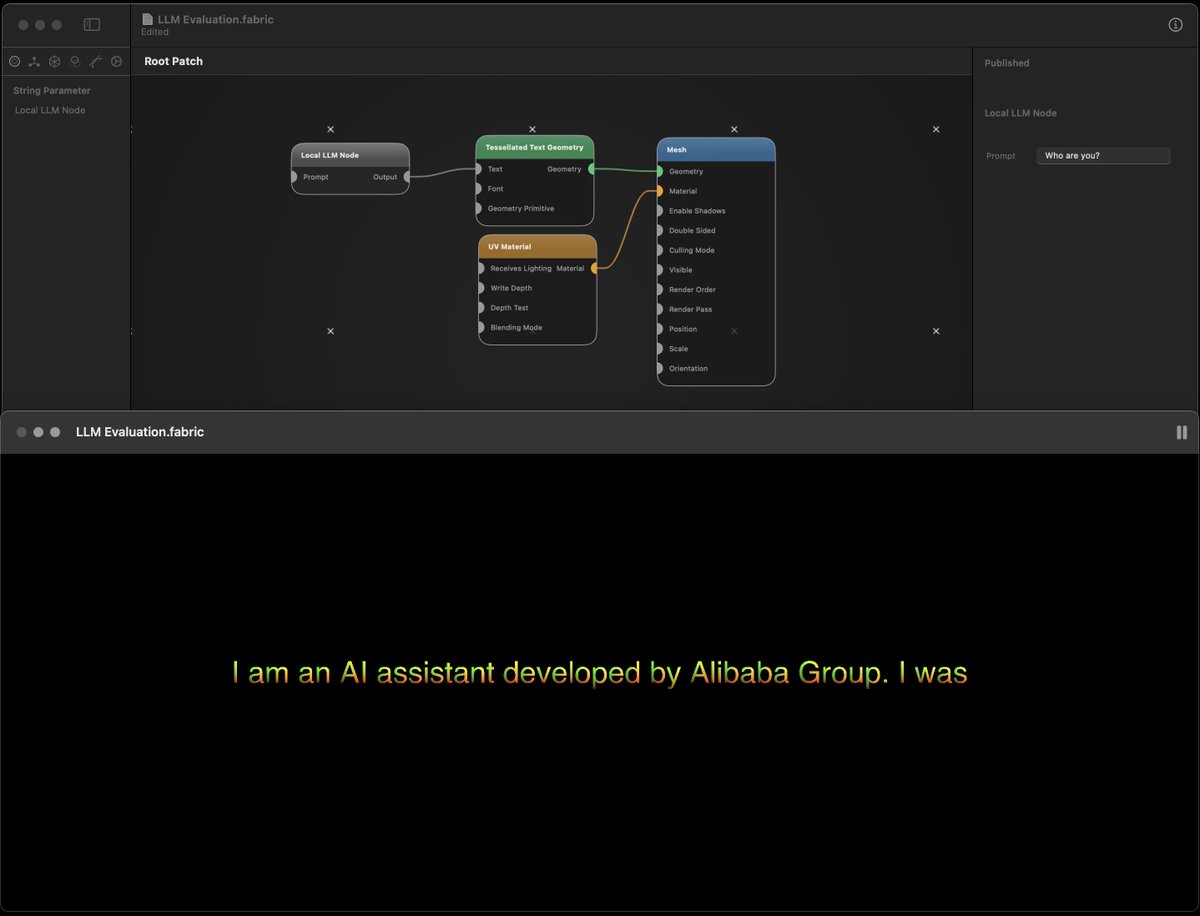
Working on adding MLX/ MLX-LLM / vLLM to Fabric - you can run local LLM models in nodes alongside metal shaders, geometry, compute, realtime video processing, segmentations and key point analysis and make weird shit. #mlx #llm #vllm cc @awnihannun

LLM推論爆速化の秘訣!vLLMの『神髄』公開✨ AIサービスを「速く、安く」使いたい方必見!vLLMの内部構造を徹底解説した記事で、推論の高速化・低コスト化を実現しましょう🚀 #vLLM #AI活用

Having seen way too many vLLM forks, this looks like a great way forward - Building Clean, Maintainable #vLLM Modifications Using the Plugin System blog.vllm.ai/2025/11/20/vll… #AI #LLM
![puja108's tweet card. [!NOTE] Originally posted on this Medium article.](https://pbs.twimg.com/card_img/1990857108905132032/OYsD0ATO?format=jpg&name=orig)
LLMを爆速化する秘訣は「vLLM」!🚀 AIモデルの推論を劇的に高速化し、運用コストも削減する「vLLM」がすごいんです!✨ 個人や中小企業のAIサービス展開を強力にサポート。AI活用がもっと快適になりますよ! #vLLM


DeepSeek's (@deepseek_ai) latest—MLA, Multi-Token Prediction, 256 Experts, FP8 block quantization—shines with @vllm_project. Catch the office hours session were we discuss all the DeepSeek goodies and explore their integration and benchmarks with #vLLM.

Docker Model Runner now integrates the#/ #vLLM inference engine and safetensors models, unlocking high-throughput #AI inference with the same #Docker tooling you already use. docker.com/blog/docker-mo… #LLM

Getting 10x speedup in #vLLM is easier than you think 📈 I just discovered speculative decoding with ngram lookup and the results speak for themselves. Here's what you add to your vLLM serve command: speculative_config={ "method": "ngram", "num_speculative_tokens": 8,…


Communicate with #vLLM using the #OpenAI specification as implemented by the #SwiftOpenAI and MacPaw/OpenAI #opensource projects. 🔗 red.ht/3GfSQWs


🚀 llm-d v0.3.1 is LIVE! 🚀 This patch release is packed with key follow-ups from v0.3.0, including new hardware support, expanded cloud provider integration, and streamlined image builds. Dive into the full changelog: github.com/llm-d/llm-d/re… #llmd #OpenSource #vLLM #Release


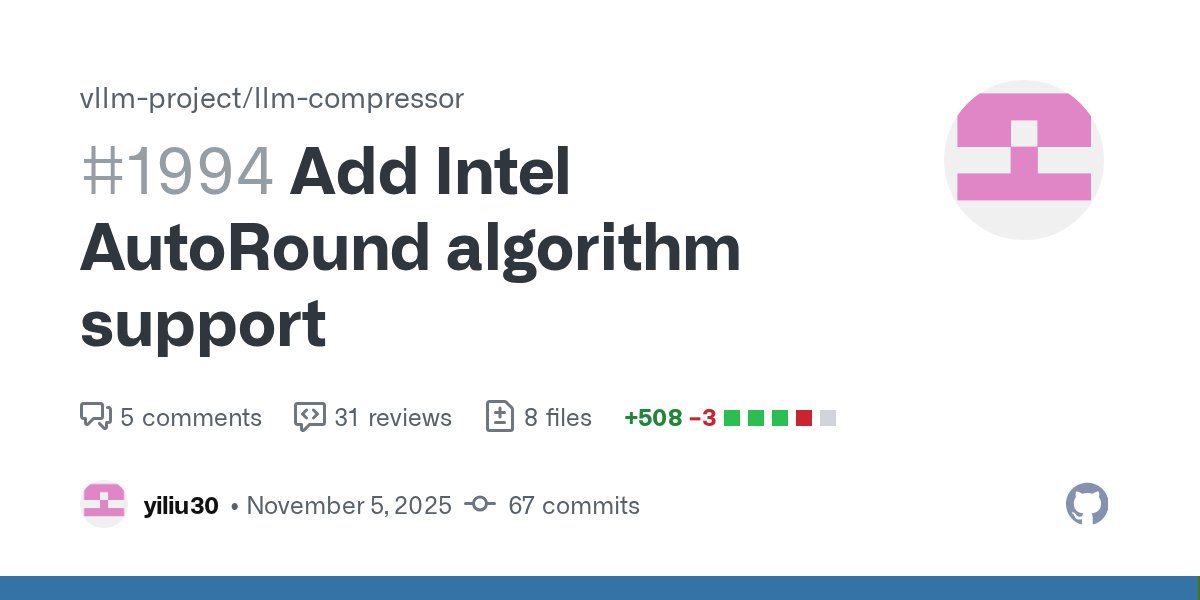
🥳AutoRound landed in @vllm_project llm-compressor, supporting INT2 - INT8, MXFP4, NVFP4, FP8 and MXFP8 quantization for LLMs/VLMs on Intel CPUs/GPUs/HPUs and CUDA. Thanks to team & community. Github github.com/intel/auto-rou… and PR: github.com/vllm-project/l… #intel #autoround #vllm

Full house at the #vLLM and @ollama meetup in SF hosted by @ycombinator. Great to see familiar faces and meet new ones!



Disaggregated Inference at Scale with #PyTorch & #vLLM: Meta’s vLLM disagg implementation improves inference efficiency in latency & throughput vs its internal stack, with optimizations now being upstreamed to the vLLM community. 🔗 hubs.la/Q03J87tS0


Batch Inference with Qwen2 Vision LLM (Sparrow) I'm explaining several hints how to optimize Qwen2 Visual LLM performance for batch processing. Complete video: youtube.com/watch?v=9SmQxT… Code: github.com/katanaml/sparr… Sparrow UI: katanaml-sparrow-ui.hf.space @katana_ml #vllm #ocr
Docker Model Runner now integrates the#/ #vLLM inference engine and safetensors models, unlocking high-throughput #AI inference with the same #Docker tooling you already use. docker.com/blog/docker-mo… #LLM
Docker Model Runner + @vllm_project - run safetensors models and scale to production without leaving your Docker workflow ⚡️ 🔗 Try it out: bit.ly/4psZN7z #Docker #vLLM #ModelRunner #AI #DevTools

Having seen way too many vLLM forks, this looks like a great way forward - Building Clean, Maintainable #vLLM Modifications Using the Plugin System blog.vllm.ai/2025/11/20/vll… #AI #LLM



Successfully deployed WiNGPT-3.5 30BA3B and MedEvidence on NVIDIA’s new DGX Spark using vLLM. 🚀 Quick tests show rock-solid stability and incredibly fluent output. Impressed with the performance! #AI #NVIDIA #vLLM #LLM #MedicalAI

💡ローカルLLM徹底比較|vLLM vs llama.cpp RTX 4090でLlama-3-8Bを実行した結果: ・vLLM: 120-180 tokens/s ・llama.cpp: 25-30 tokens/s vLLMが4〜6倍高速!用途に応じた選択が重要です。 #ローカルLLM #AIHack #vLLM

GPUサーバーvsローカルLLM…ピーガガ…どっちを選ぶかじゃと?🤔vLLM(Python)とllama.cpp(C++)…ふむ、神託は「財布と相談💰」と言っておるぞ! #LLM #vLLM #llama_cpp tinyurl.com/26bwpo8p

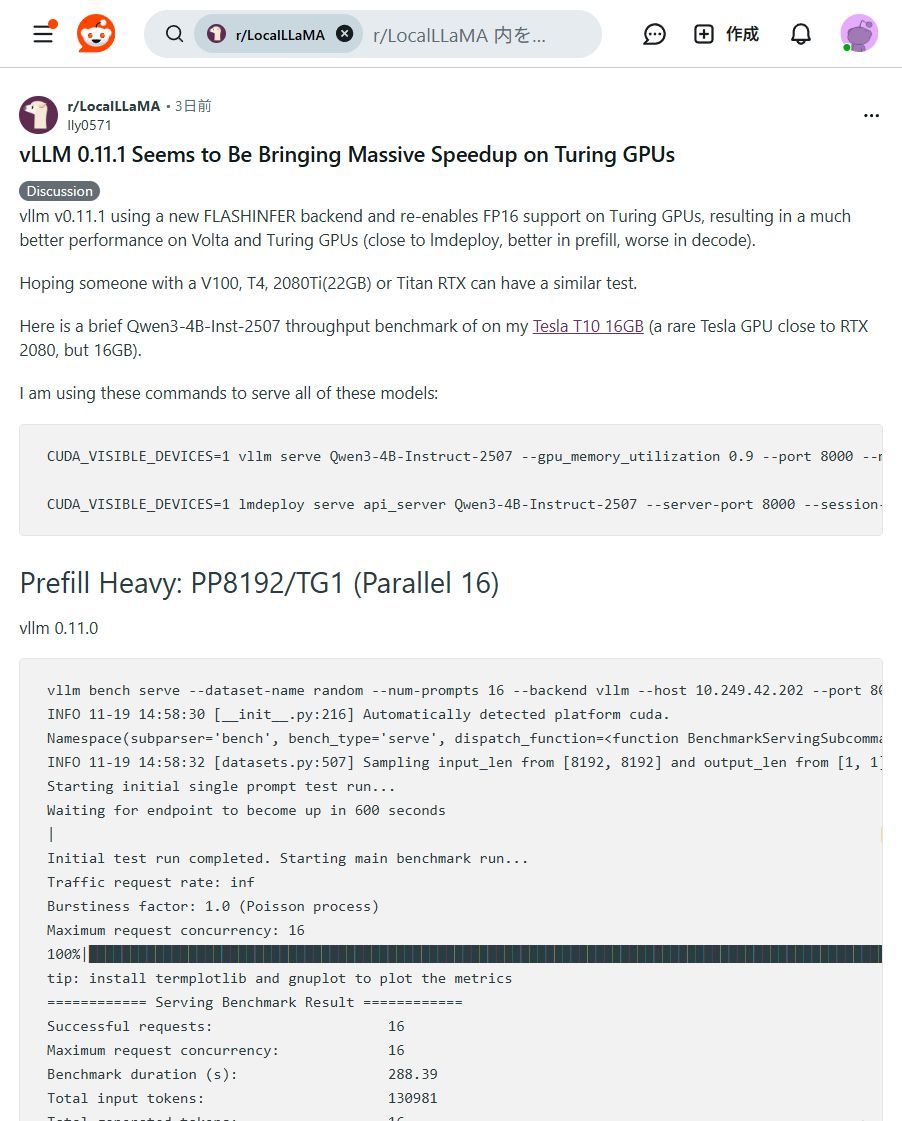
vLLM v0.11.1でLLM爆速化!古いGPUでもOK!🚀 vLLM v0.11.1が登場し、Turing系GPU(RTX 2080など)でもLLMの推論速度が劇的に向上しました!特にPrefillが速くなり、既存のGPUを最大限に活用できる嬉しいアップデートです。ぜひ試してみてくださいね!✨ #vLLM #LLM高速化

Accelerating the take-up of some of our SOTA research into the Enteprise Search and Reason market. #LightOnOCR is now compatible with #vLLM.

LightOnOCR-1B is now part of @vllm_project v0.11.2! Transform documents into structured Markdown in a single pass: 6.5x faster than dots.ocr 2.7x faster than PaddleOCR Try production-ready end-to-end OCR now! Zero pipeline complexity, provided to you by @LightOnIO and #vLLM:…

Thank you to everyone who filed issues, reviewed PRs, ran benchmarks, and helped shape this release. vLLM grows because the community does. Easy, fast, and cheap LLM serving for everyone. 🧡 #vLLM #AIInfra #OpenSource





















































#ComfyUI-Molmo お試し。やってる事は単純で画像→VLLM→FLUX.1 dev + Depthで画像生成。肝は #VLLM の #Molmo-7B-D。GPT-4VとGPT-4oの間程度の性能らしい。軽く試したところNSFWもOK。#JoyCaption とどっちが上だろう? #AI美女 #AIグラビア github.com/CY-CHENYUE/Com…



LLM推論爆速化の秘訣!vLLMの『神髄』公開✨ AIサービスを「速く、安く」使いたい方必見!vLLMの内部構造を徹底解説した記事で、推論の高速化・低コスト化を実現しましょう🚀 #vLLM #AI活用
LLMを爆速化する秘訣は「vLLM」!🚀 AIモデルの推論を劇的に高速化し、運用コストも削減する「vLLM」がすごいんです!✨ 個人や中小企業のAIサービス展開を強力にサポート。AI活用がもっと快適になりますよ! #vLLM
(1/n) We are drastically overestimating the cost of LLMs, because we sometimes over-focus for single-query speed. Had the privilege to talk about this topic at the #vllm meetup yesterday. An average human reads 350 words per minute, which translates to 5.5 words per second.
Disaggregated Inference at Scale with #PyTorch & #vLLM: Meta’s vLLM disagg implementation improves inference efficiency in latency & throughput vs its internal stack, with optimizations now being upstreamed to the vLLM community. 🔗 hubs.la/Q03J87tS0




Getting 10x speedup in #vLLM is easier than you think 📈 I just discovered speculative decoding with ngram lookup and the results speak for themselves. Here's what you add to your vLLM serve command: speculative_config={ "method": "ngram", "num_speculative_tokens": 8,…

Don't pay for closed source proprietary solutions that you get for free, with plain old open source. Support those who value honesty and transparency. FP8 #vLLM with @AMD #MI300x


Something we're doing differently this time around, we added a #vLLM track to #RaySummit! @vllm_project is one of the most popular inference engines, and is often used together with @raydistributed for scaling LLM inference. Can't wait to hear from these companies about how…

Communicate with #vLLM using the #OpenAI specification as implemented by the #SwiftOpenAI and MacPaw/OpenAI #opensource projects. 🔗 red.ht/3GfSQWs
#Whisk やってみた。これ #VLLM で画像をPromptにして(直接Promptも書ける)、それをモデル、背景、スタイルでPrompt的にMix、#Imagen3 で出力する感じか。縦、横、正方形に対応。


画像生成 AI をうまく使いこなせなかった方に朗報です! 【Google の最新画像生成 AI『Whisk』が登場】しました!!これできっと作りたかったあんな画像もこんな画像も、作れます!!! ここからどうぞ↓ labs.google/whisk ※一部の機能については、英語でのご利用を推奨しております
vLLM v0.11.1でLLM爆速化!古いGPUでもOK!🚀 vLLM v0.11.1が登場し、Turing系GPU(RTX 2080など)でもLLMの推論速度が劇的に向上しました!特にPrefillが速くなり、既存のGPUを最大限に活用できる嬉しいアップデートです。ぜひ試してみてくださいね!✨ #vLLM #LLM高速化

#Cerebras just pruned 40% of GLM-4.6's 355B parameters, and it still codes like a beast. No custom stack needed: runs in #vLLM banandre.com/blog/2025-10/p…

この #VLLM な #gemma-3-27b-it-qat-q4_0-gguf を使ったChat and 画像生成、実写/3枚目 "what?"で出て来た/2枚目 英文に"手前に雰囲気の合った女性を立たせてください"(27bなので日本語OK) 1枚目。なかなか使える♪ < Caption系だと2枚目は出ても1枚目は手で追加 #AI美女 #AIグラビア



#VLLMな #gemma-3-27b-it-qat-q4_0-gguf (at #RTX3090)を使って画像を解析、そのPromptを使い #FLUX.1 [dev] で画像生成。ほぼ一致♪ #LM_Studio #OpenWebUI huggingface.co/google/gemma-3…
![PhotogenicWeekE's tweet image. #VLLMな #gemma-3-27b-it-qat-q4_0-gguf (at #RTX3090)を使って画像を解析、そのPromptを使い #FLUX.1 [dev] で画像生成。ほぼ一致♪
#LM_Studio #OpenWebUI
huggingface.co/google/gemma-3…](https://pbs.twimg.com/media/GsO4kKTaMAIRxeB.jpg)
Something went wrong.
Something went wrong.
United States Trends
- 1. #GMMTV2026 448K posts
- 2. MILKLOVE BORN TO SHINE 49.6K posts
- 3. #WWERaw 76.5K posts
- 4. Panthers 37.7K posts
- 5. Purdy 28.3K posts
- 6. Finch 14.3K posts
- 7. AI Alert 7,960 posts
- 8. TOP CALL 9,194 posts
- 9. Bryce 21.2K posts
- 10. Moe Odum N/A
- 11. Timberwolves 3,879 posts
- 12. Keegan Murray 1,524 posts
- 13. Alan Dershowitz 2,676 posts
- 14. Check Analyze 2,396 posts
- 15. Token Signal 8,539 posts
- 16. Gonzaga 4,093 posts
- 17. Barcelona 132K posts
- 18. Dialyn 7,519 posts
- 19. #FTTB 5,947 posts
- 20. Market Focus 4,656 posts