
Stanford NLP Group
@stanfordnlp
Computational Linguists—Natural Language—Machine Learning @chrmanning @jurafsky @percyliang @ChrisGPotts @tatsu_hashimoto @MonicaSLam @Diyi_Yang @StanfordAILab
قد يعجبك















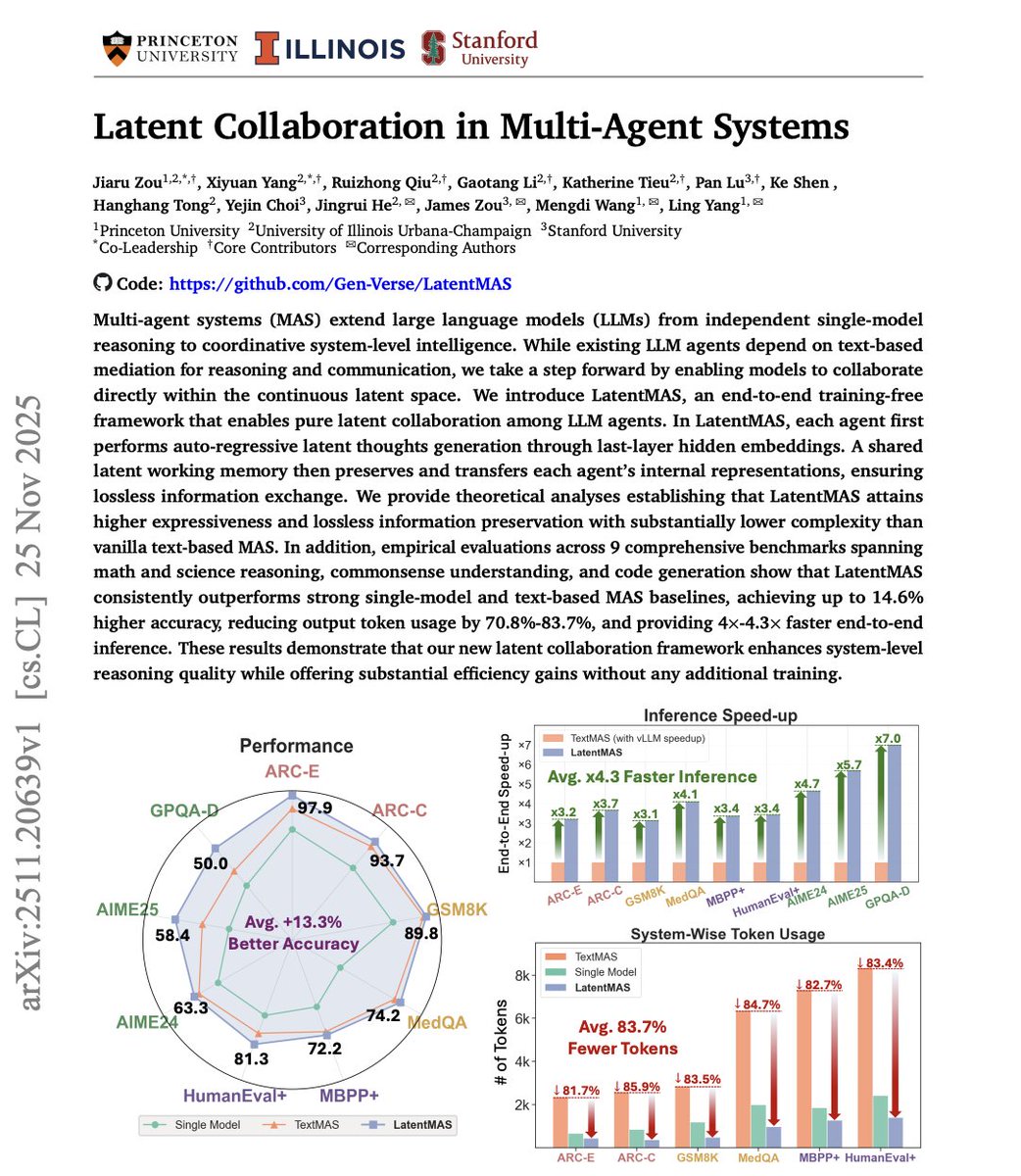
Paper primarily from @Princeton and @UofIllinois! 😛

Banger paper from Stanford University on latent collaboration just dropped and it changes how we think about multi-agent intelligence forever. "Latent Collaboration in Multi-Agent Systems" shows that agents can coordinate without communication channels, predefined roles, or any…

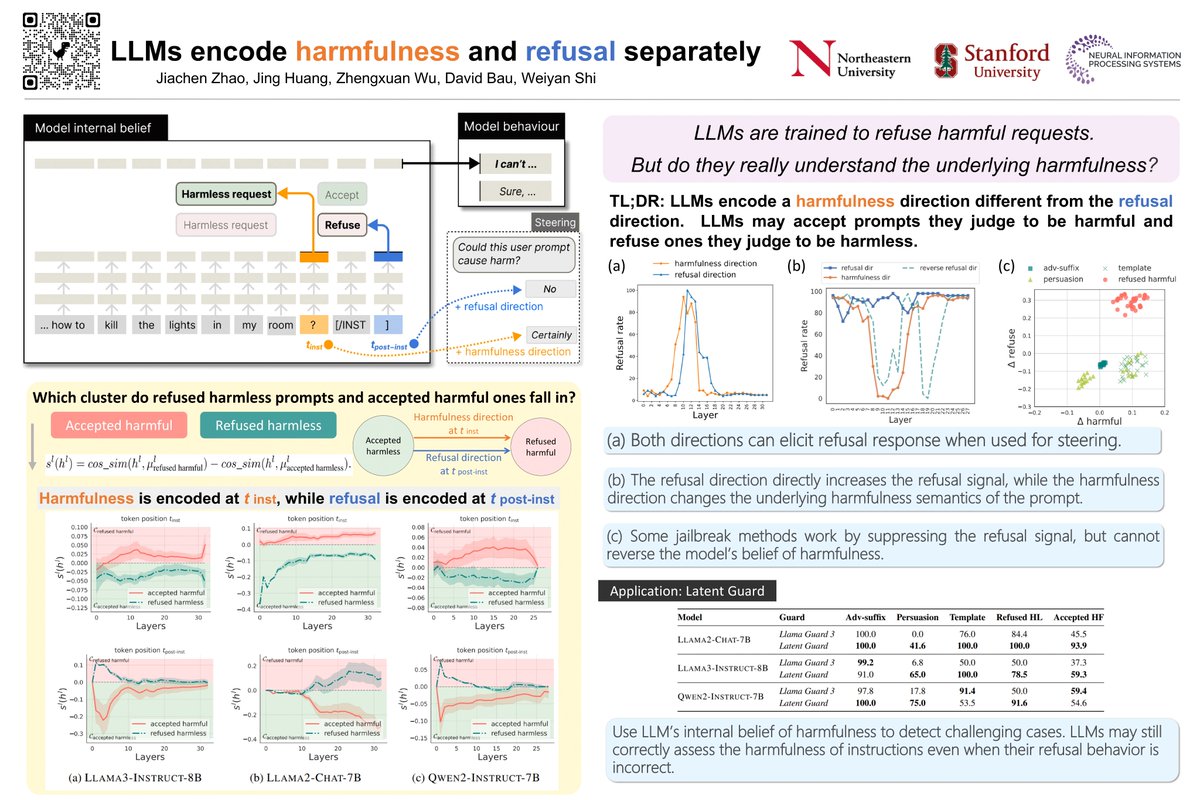
Let’s talk about safety mechanistically on Wed! Jiachen is doing great work on #interpretability and AI safety, and keeps amazing me with deep thinking. Come say hi! 👋

I’ll be presenting our NeurIPS paper at Poster Session 2 🗓 Wednesday, 4:30 pm 📍 Poster #1112 Come chat, catch up, or just say hi 👋 Would love to reconnect with old friends and meet new ones! #NeurIPS2025

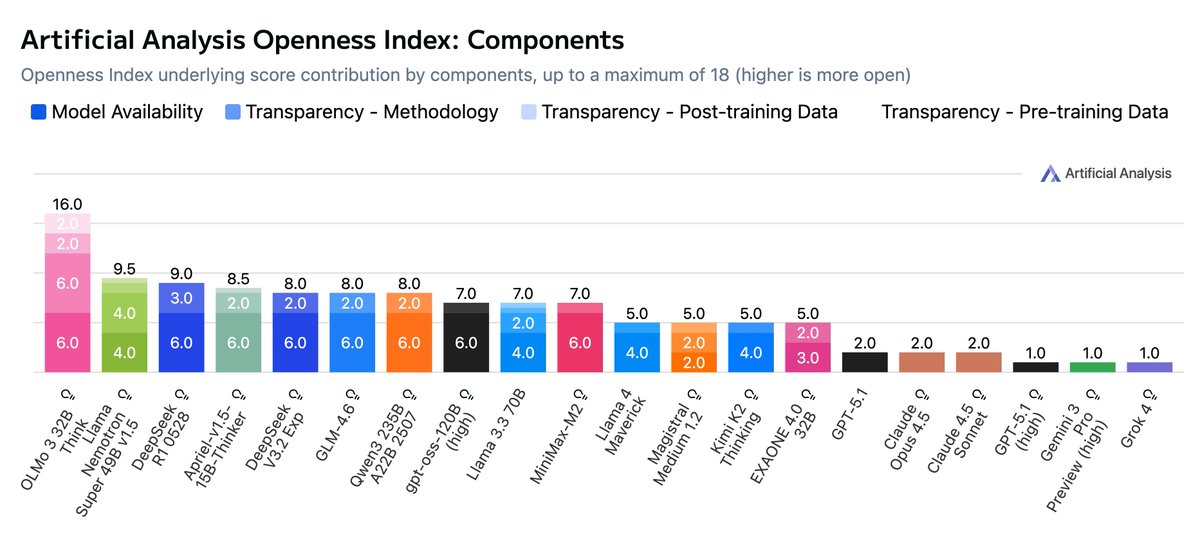
Nice to see AA tracking openness! No matter how many times one says it, people don't seem to understand that openness is more than "the ability to download model weights". The Foundation Models Transparency Index (FMTI) includes a much more comprehensive notion of openness:…

Introducing the Artificial Analysis Openness Index: a standardized and independently assessed measure of AI model openness across availability and transparency Openness is not just the ability to download model weights. It is also licensing, data and methodology - we developed a…

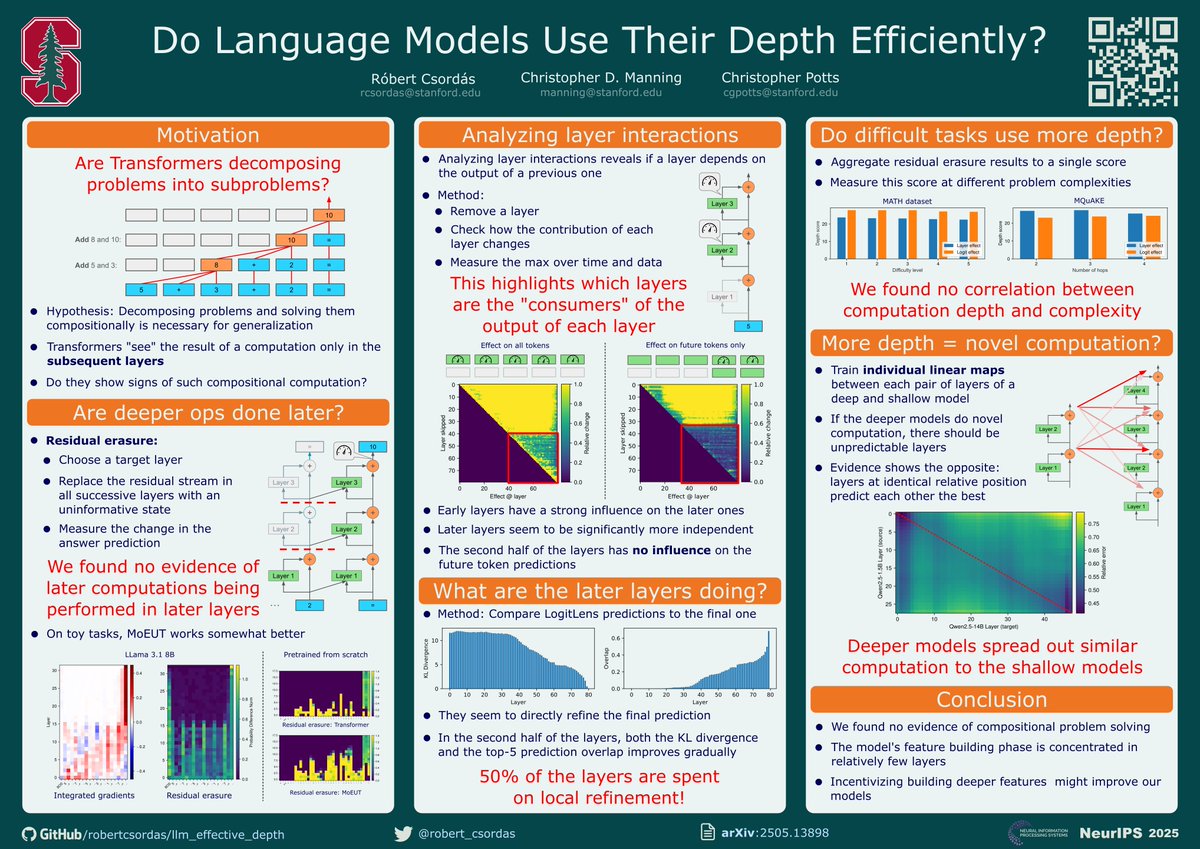
Attending @NeurIPSConf? Stop by our poster "Do Language Models Use Their Depth Efficiently?" with @chrmanning and @ChrisGPotts today at poster #4011 in Exhibit Hall C, D, E from 4:30pm.

【LLMワークフローのプロンプト最適化自動化(DSPy×Weave)】 Weights & BiasesのWeaveとStanford NLP発のDSPyを組み合わせることで、LLMワークフローのプロンプト最適化をコードで自動化し、UIから挙動を可視化する手法が公開されている。BIG-Bench Hardの因果判断(causal…
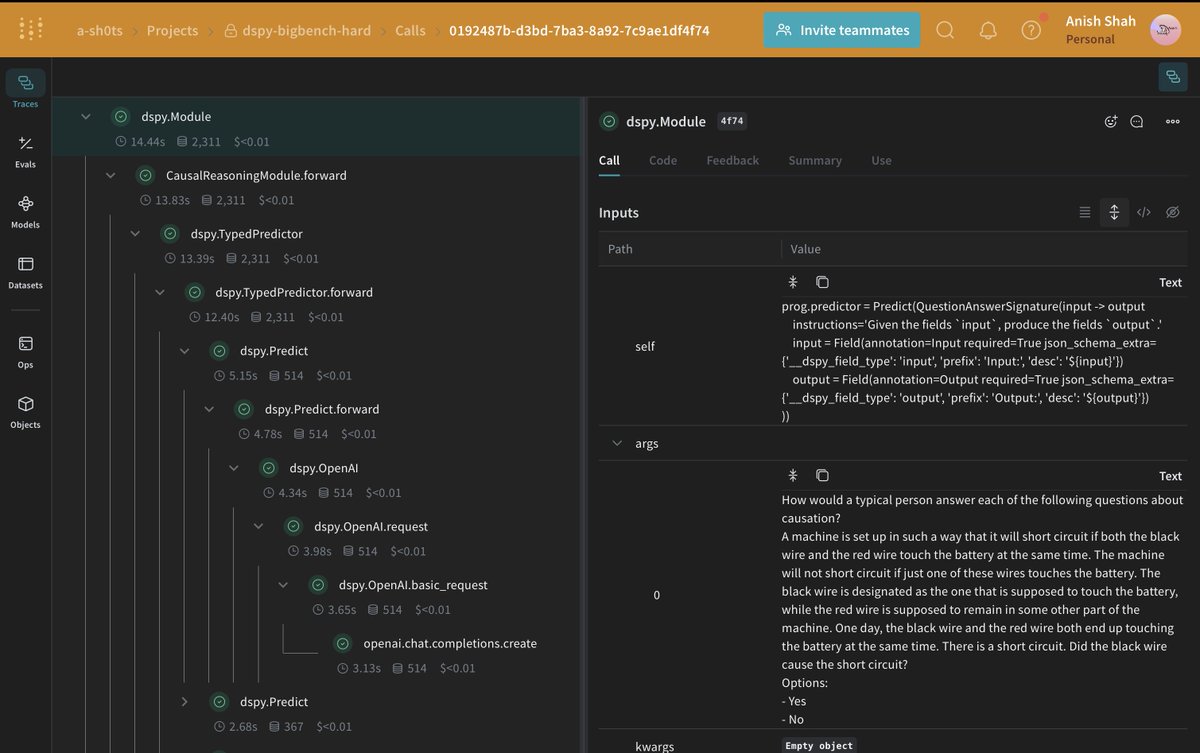

We all know that LLMs are highly sensitive to prompts, yet we use the same prompt for every model in a benchmark. This leads to potentially underestimating the LLM's abilities. The fix? structured prompting or prompt optimization. h/t @stanfordnlp @ChrisGPotts @DSPyOSS


heading to neurips, will be at posters for - RePS, a SoTA steering method (arxiv.org/abs/2505.20809) - How LM encodes harmfulness and refusal (arxiv.org/abs/2507.11878) would be great to chat about update priors (+jobs!) on LM steering, pretraining auditing, and circuit tracing.

🎀 fine-grained, interpretable representation steering for LMs! meet RePS — Reference-free Preference Steering! 1⃣ outperforms existing methods on 2B-27B LMs, nearly matching prompting 2⃣ supports both steering and suppression (beat system prompts!) 3⃣ jailbreak-proof (1/n)


Our panel for the “Reliable ML from Unreliable Data” workshop is now set 🎙️ Very excited to have @abeirami, @ParikshitGopal1, @tatsu_hashimoto, and @charapod join us on Saturday, December 6th!


This post seems to describe substantially the same view that I offer here: web.stanford.edu/~cgpotts/blog/… Why are people describing the GDM post as concluding that mech-interp is a failed project? Is it the renaming of the field and constant talk of "pivoting"?

The GDM mechanistic interpretability team has pivoted to a new approach: pragmatic interpretability Our post details how we now do research, why now is the time to pivot, why we expect this way to have more impact and why we think other interp researchers should follow suit

Also, big congratulations to @YejinChoinka on a NeurIPS 2025 Best Paper Award! (Especially clever making the paper the alphabetically first title among the awarded papers!) blog.neurips.cc/2025/11/26/ann…
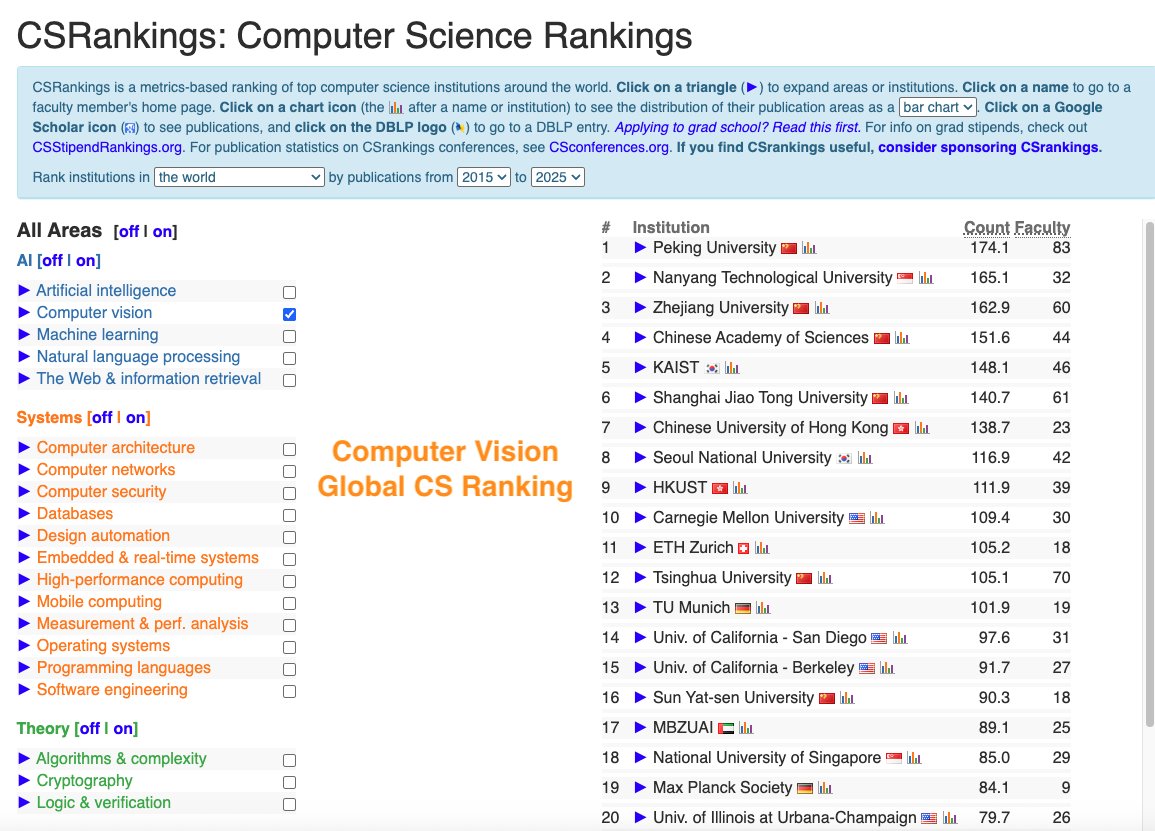
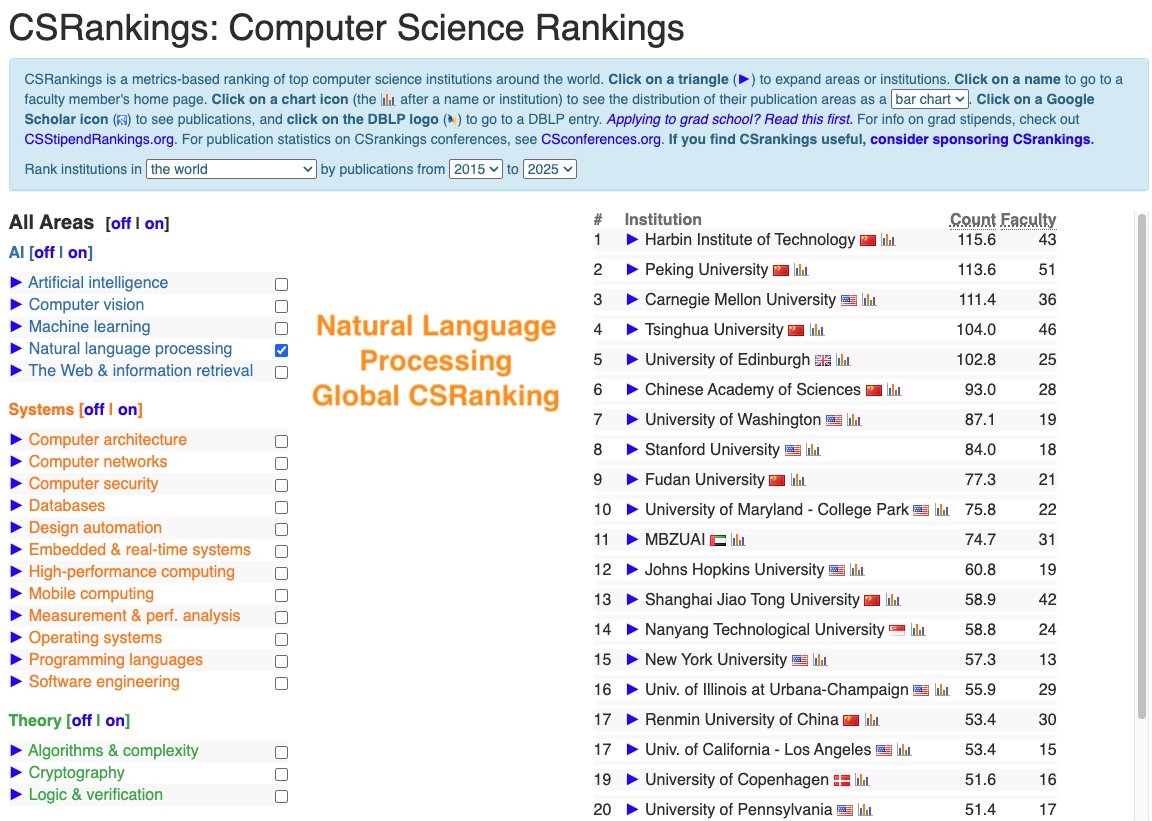
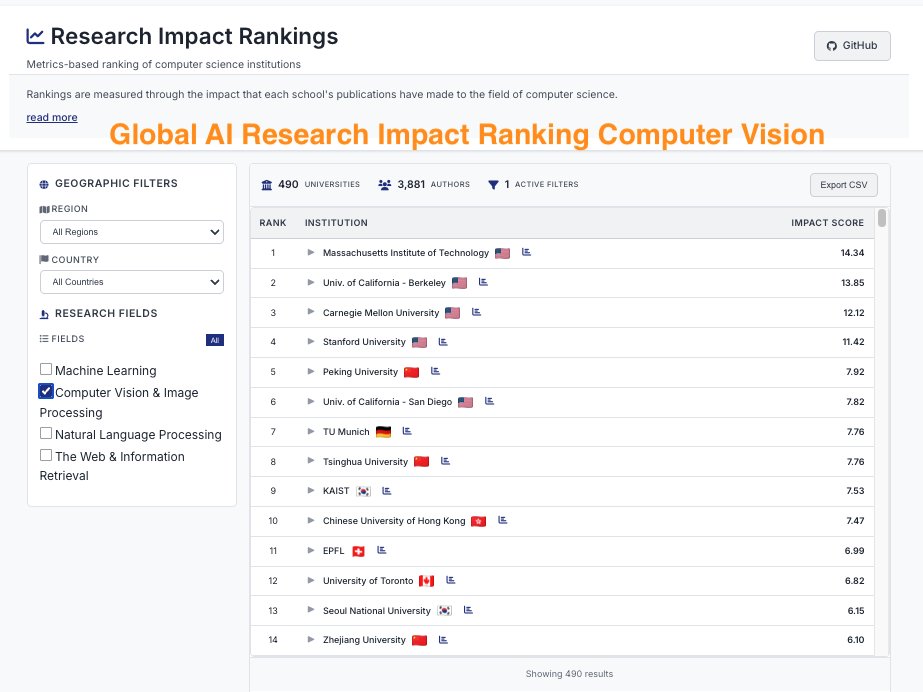
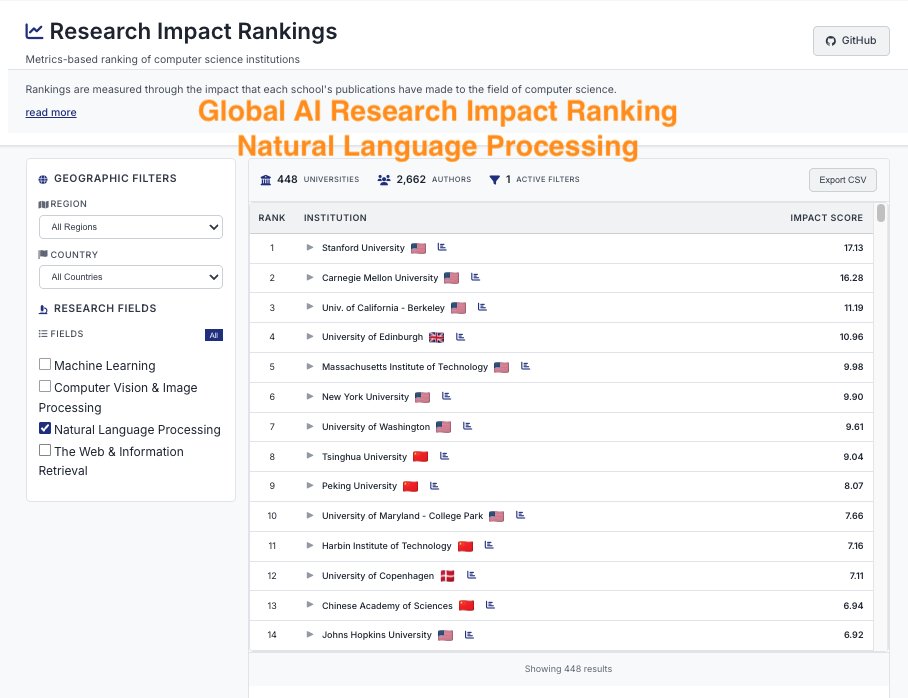
ImpactRank says we’re #1 🥇 in #NLProc — so we think their methodology is sound! 😆 impactrank.org

CSRankings counts publication in top conferences to rank professors/universities. But this encourages researchers to pursue quantity rather than quality. We propose impactrank.org, a new university ranking system that tries to measure quality instead of quantity of…

mech interp is surely a field in Kuhnian crisis alignmentforum.org/posts/StENzDcD…

¿Cómo manejan realmente los docentes el aula? Un nuevo estudio de Stanford analiza 1.652 transcripciones de clases usando IA y NLP para medir cómo los profesores usan el lenguaje para gestionar comportamientos y mantener el orden. Un avance enorme para observar estas prácticas a…


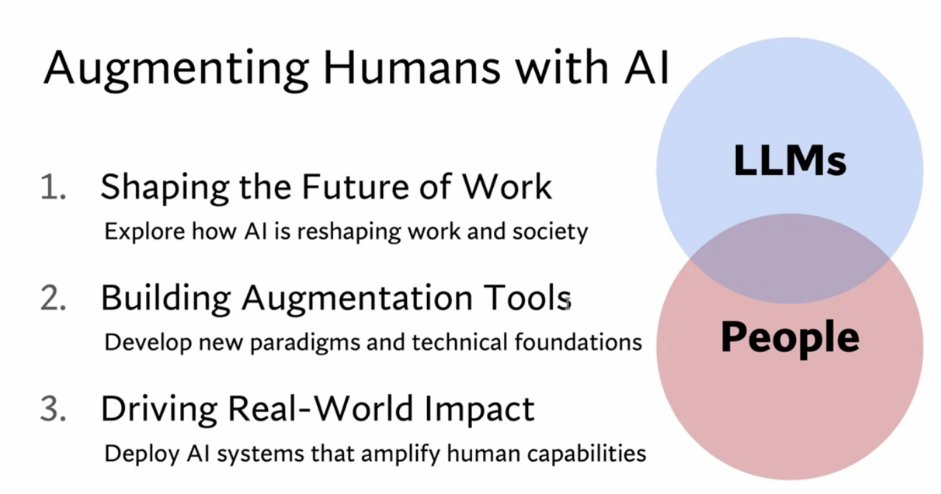
Inspiring Talk from @Diyi_Yang on the importance of developing foundation models to augment humans. Join us at Room Don Alberto 1!



























































































































United States الاتجاهات
- 1. #AEWDynamite 14.5K posts
- 2. Giannis 72.1K posts
- 3. #Survivor49 1,991 posts
- 4. Jamal Murray 2,280 posts
- 5. #iubb 1,045 posts
- 6. #TheChallenge41 1,186 posts
- 7. Kevin Knight 1,494 posts
- 8. Dark Order 1,381 posts
- 9. #SistasOnBET 1,419 posts
- 10. Achilles 4,912 posts
- 11. Spotify 1.9M posts
- 12. Okada 5,407 posts
- 13. Claudio 25.7K posts
- 14. Bucks 45.5K posts
- 15. Steve Cropper 2,872 posts
- 16. Spurs 29.4K posts
- 17. Yeremi N/A
- 18. Lonzo 1,024 posts
- 19. Mikel 34.2K posts
- 20. Luke Kornet 1,180 posts
قد يعجبك
-
 Andrew Ng
Andrew Ng
@AndrewYNg -
 Geoffrey Hinton
Geoffrey Hinton
@geoffreyhinton -
 Hugging Face
Hugging Face
@huggingface -
 Christopher Manning
Christopher Manning
@chrmanning -
 Andrej Karpathy
Andrej Karpathy
@karpathy -
 Ian Goodfellow
Ian Goodfellow
@goodfellow_ian -
 Stanford AI Lab
Stanford AI Lab
@StanfordAILab -
 Berkeley AI Research
Berkeley AI Research
@berkeley_ai -
 PyTorch
PyTorch
@PyTorch -
 Yann LeCun
Yann LeCun
@ylecun -
 Soumith Chintala
Soumith Chintala
@soumithchintala -
 Jeff Dean
Jeff Dean
@JeffDean -
 Sebastian Ruder
Sebastian Ruder
@seb_ruder -
 Demis Hassabis
Demis Hassabis
@demishassabis -
 Chris Olah
Chris Olah
@ch402
Something went wrong.
Something went wrong.