
내가 좋아할 만한 콘텐츠














Highly recommend the Tinker Research and Teaching Grants: thinkingmachines.ai/blog/tinker-re… We found it very helpful when updating Stanford CS 329X: Human-Centered LLMs this year - many students requested to keep using it with creative course project ideas after the assignment.


Today we’re announcing research and teaching grants for Tinker: credits for scholars and students to fine-tune and experiment with open-weight LLMs. Read more and apply at: thinkingmachines.ai/blog/tinker-re…
The innovation ecosystem behind today’s dramatic AI wave was developed through open science and open development. With corporate AI labs turning secretive, universities and nonprofits must reclaim innovating with open AI research for the public good. hai.stanford.edu/news/universit…


Marin project is insanely cool! and they get stuff done

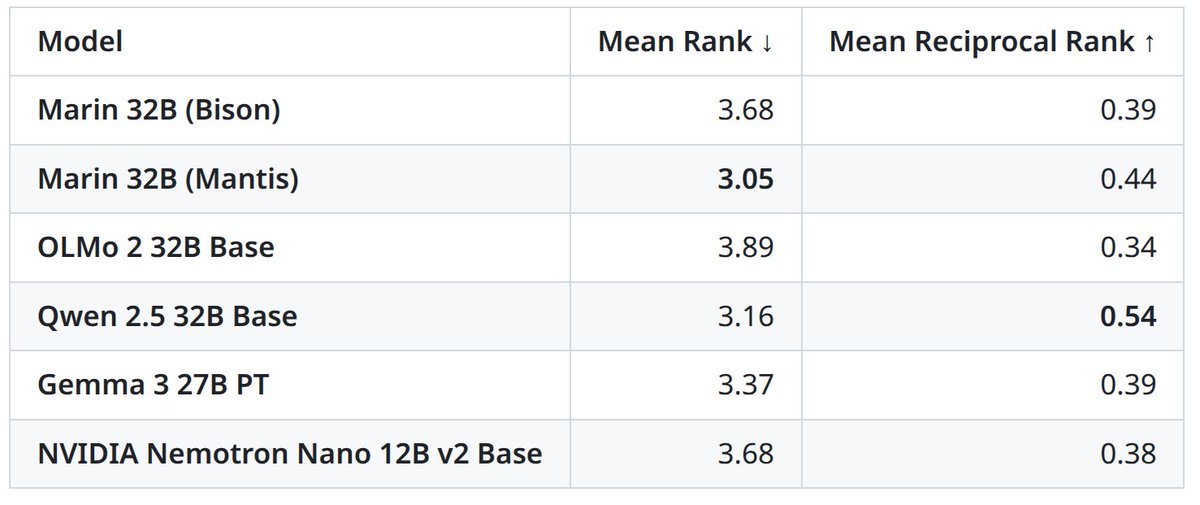
⛵Marin 32B Base (mantis) is done training! It is the best open-source base model (beating OLMo 2 32B Base) and it’s even close to the best comparably-sized open-weight base models, Gemma 3 27B PT and Qwen 2.5 32B Base. Ranking across 19 benchmarks:

Yesterday I asked what makes you happy. 226 voted--61% said family & friends, like those AI researchers at the panel. Not AI, just the people around us. This resonates with Harvard's 87-year study on happiness. Their conclusion: happiness is not about money/fame/success, it's…
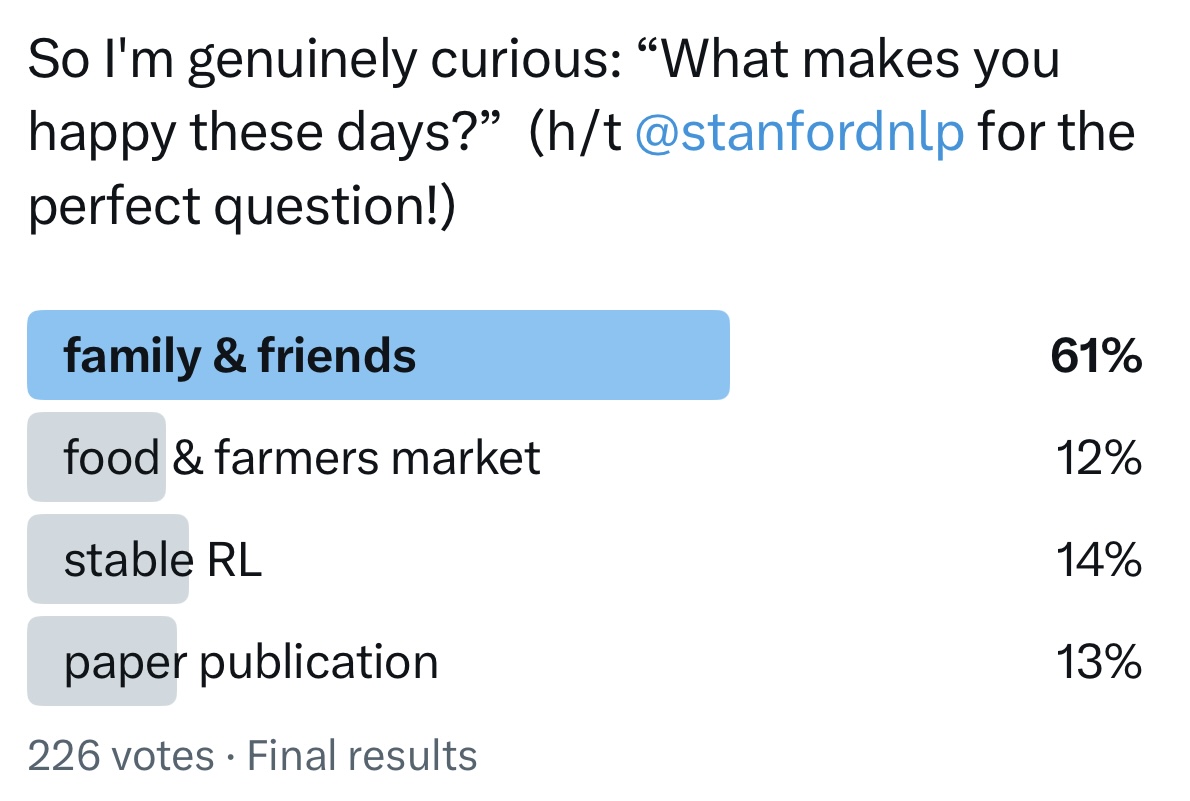
I heard the best question at an AI panel recently: "what makes you happy these days?" Top AI researchers answered: my partner, my family, farmers market, good food. Nothing about AI—everything about the humans around us. In an industry burning out, maybe that's the answer?
@karpathy observed LLMs are "silently collapsed...only know 3 jokes". We prove this is mathematically inevitable due to RLHF + human psychology. But these capabilities aren't lost, just hidden – and easily restored. This means AI benchmarks are measuring training artifacts.🧵


🥳I have just added Marin gptq and awq quantization support to GPT-QModel with the first release of a Marin W4A16 gptq quant on HF. dl link in comments. 👇 @percyliang @dlwh
⛵Marin 32B Base (mantis) is done training! It is the best open-source base model (beating OLMo 2 32B Base) and it’s even close to the best comparably-sized open-weight base models, Gemma 3 27B PT and Qwen 2.5 32B Base. Ranking across 19 benchmarks:
⛵Marin 32B Base (mantis) is done training! It is the best open-source base model (beating OLMo 2 32B Base) and it’s even close to the best comparably-sized open-weight base models, Gemma 3 27B PT and Qwen 2.5 32B Base. Ranking across 19 benchmarks:

1/4 Following up on our launch of Tongyi DeepResearch: We're now releasing the full technical report! Dive deep into the technology and insights behind our 30B (A3B) open-source web agent that achieves SOTA performance: 32.9 on Humanity's Last Exam, 43.4 on BrowseComp, and 46.7…


Someone should do an analysis of the cumulative impact of Chris Manning - Research he co-produced - Students he advised who went on to be top faculty and industry leaders - Untold distributed impact from textbooks, open-source software, and online lectures Absolutely incredible

236 direct/indirect PhD students!! Based on OpenReview data, an interactive webpage: prakashkagitha.github.io/manningphdtree/ Your course, NLP with Deep learning - Winter 2017, on YouTube, was my introduction to building deep learning models. This is the least I could do to say Thank You!!


Marin, which @percyliang, @dlwh, and many others are building is *fully open* (not just open weights) and has been used to build high-quality, competitive models. Come to the talk next week at Ray Summit 😀

What I found most surprising from this graph is that @percyliang has somehow already eclipsed Dan Klein in number of graduated PhD students and is close to catching @chrmanning Different styles in how they have built their groups, in different eras, but nonetheless surprising
236 direct/indirect PhD students!! Based on OpenReview data, an interactive webpage: prakashkagitha.github.io/manningphdtree/ Your course, NLP with Deep learning - Winter 2017, on YouTube, was my introduction to building deep learning models. This is the least I could do to say Thank You!!

我原定的计划是CS229->CS224n->CS336(期间的论文阅读量能应付两位导师就好),学完这些课之后再all in多智能体论文

Excited to talk about Augmenting Humans with LLMs 💪 at 2pm today at The University of Michigan Symposium on Human-Centered AI 🤩 What a beautiful campus! 📍


We recorded a bunch of people actually working on their computers (!) and then compared agent performance to actual human workflows. Awesome paper led by @ZhiruoW :)

Agents are joining us at work -- coding, writing, design. But how do they actually work, especially compared to humans? Their workflows tell a different story: They code everything, slow down human flows, and deliver low-quality work fast. Yet when teamed with humans, they shine…

Thanks! I want to stick with the overall assessment on the slide, though, especially the juxtaposition of the final part of the Lewis quotation with my concern about it on the right. I suspect my concern extends to your claim about what we can/should keep separate!

@ZhiruoW 's research compares AI agents vs humans across real work tasks (data analysis, engineering, design, writing). Key findings: 👉Agents are 88% faster & 90-96% cheaper 👉BUT produce lower quality work, often fabricate data to mask limitations 👉Agents code everything,…

Agents are joining us at work -- coding, writing, design. But how do they actually work, especially compared to humans? Their workflows tell a different story: They code everything, slow down human flows, and deliver low-quality work fast. Yet when teamed with humans, they shine…
Check out our: 📄 Paper: arxiv.org/abs/2510.22780 🧩 Workflow induction tool: github.com/zorazrw/workfl… With the fantastic team @EchoShao8899 @oshaikh13 @dan_fried @gneubig @Diyi_Yang at @LTIatCMU & @stanfordnlp


CS 276 from @stanfordnlp is where I met my co-founder at Turing! (@krishnanvijay) Such a fun class taught by @chrmanning & @WittedNote which sparked a lifelong passion in AI. (Along with CS 229 by @AndrewYNg)
Today, we’re overjoyed to have a 25th Anniversary Reunion of @stanfordnlp. So happy to see so many of our former students back at @Stanford. And thanks to @StanfordHAI for the venue!

Analyzing agent trajectories has become a new canonical way for evaluation. Yet most trajectories operate at the action level - dense but semantically shallow. We define 𝙬𝙤𝙧𝙠𝙛𝙡𝙤𝙬 as a higher-level abstraction and release a toolkit to induce it from raw actions for both…

Agents are joining us at work -- coding, writing, design. But how do they actually work, especially compared to humans? Their workflows tell a different story: They code everything, slow down human flows, and deliver low-quality work fast. Yet when teamed with humans, they shine…




















































































































United States 트렌드
- 1. VMIN 16K posts
- 2. seokjin 233K posts
- 3. Good Saturday 18.5K posts
- 4. Chovy 11.9K posts
- 5. #SaturdayVibes 2,958 posts
- 6. Nigeria 458K posts
- 7. Spring Day 49K posts
- 8. GenG 6,428 posts
- 9. #LoVeMeAgain 29.4K posts
- 10. VOCAL KING TAEHYUNG 31.6K posts
- 11. #SaturdayMotivation 1,054 posts
- 12. Happy New Month 212K posts
- 13. Merry Christmas 11.5K posts
- 14. #saturdaymorning 1,350 posts
- 15. #AllSaintsDay 1,178 posts
- 16. Game 7 78.5K posts
- 17. Shirley Temple 1,062 posts
- 18. jungkook 635K posts
- 19. Tinubu 50.8K posts
- 20. Wrigley N/A
내가 좋아할 만한 콘텐츠
-
 Andrew Ng
Andrew Ng
@AndrewYNg -
 Hugging Face
Hugging Face
@huggingface -
 Christopher Manning
Christopher Manning
@chrmanning -
 Andrej Karpathy
Andrej Karpathy
@karpathy -
 Ian Goodfellow
Ian Goodfellow
@goodfellow_ian -
 Stanford AI Lab
Stanford AI Lab
@StanfordAILab -
 Berkeley AI Research
Berkeley AI Research
@berkeley_ai -
 PyTorch
PyTorch
@PyTorch -
 Yann LeCun
Yann LeCun
@ylecun -
 Soumith Chintala
Soumith Chintala
@soumithchintala -
 Jeff Dean
Jeff Dean
@JeffDean -
 Sebastian Ruder
Sebastian Ruder
@seb_ruder -
 Chris Olah
Chris Olah
@ch402
Something went wrong.
Something went wrong.