
Stanford NLP Group
@stanfordnlp
Computational Linguists—Natural Language—Machine Learning @chrmanning @jurafsky @percyliang @ChrisGPotts @tatsu_hashimoto @MonicaSLam @Diyi_Yang @StanfordAILab
Anda mungkin suka
















heading to neurips, will be at posters for - RePS, a SoTA steering method (arxiv.org/abs/2505.20809) - How LM encodes harmfulness and refusal (arxiv.org/abs/2507.11878) would be great to chat about update priors (+jobs!) on LM steering, pretraining auditing, and circuit tracing.

🎀 fine-grained, interpretable representation steering for LMs! meet RePS — Reference-free Preference Steering! 1⃣ outperforms existing methods on 2B-27B LMs, nearly matching prompting 2⃣ supports both steering and suppression (beat system prompts!) 3⃣ jailbreak-proof (1/n)


Our panel for the “Reliable ML from Unreliable Data” workshop is now set 🎙️ Very excited to have @abeirami, @ParikshitGopal1, @tatsu_hashimoto, and @charapod join us on Saturday, December 6th!


This post seems to describe substantially the same view that I offer here: web.stanford.edu/~cgpotts/blog/… Why are people describing the GDM post as concluding that mech-interp is a failed project? Is it the renaming of the field and constant talk of "pivoting"?

The GDM mechanistic interpretability team has pivoted to a new approach: pragmatic interpretability Our post details how we now do research, why now is the time to pivot, why we expect this way to have more impact and why we think other interp researchers should follow suit

Also, big congratulations to @YejinChoinka on a NeurIPS 2025 Best Paper Award! (Especially clever making the paper the alphabetically first title among the awarded papers!) blog.neurips.cc/2025/11/26/ann…
ImpactRank says we’re #1 🥇 in #NLProc — so we think their methodology is sound! 😆 impactrank.org

CSRankings counts publication in top conferences to rank professors/universities. But this encourages researchers to pursue quantity rather than quality. We propose impactrank.org, a new university ranking system that tries to measure quality instead of quantity of…
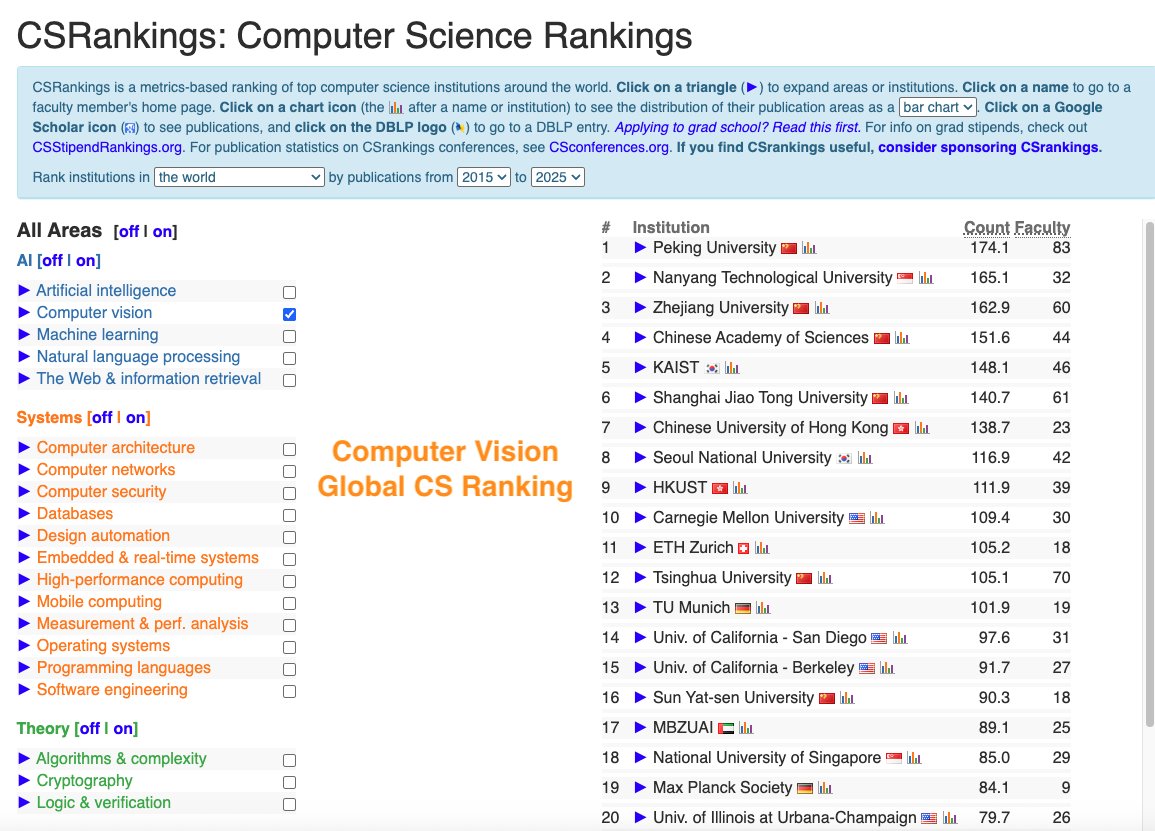
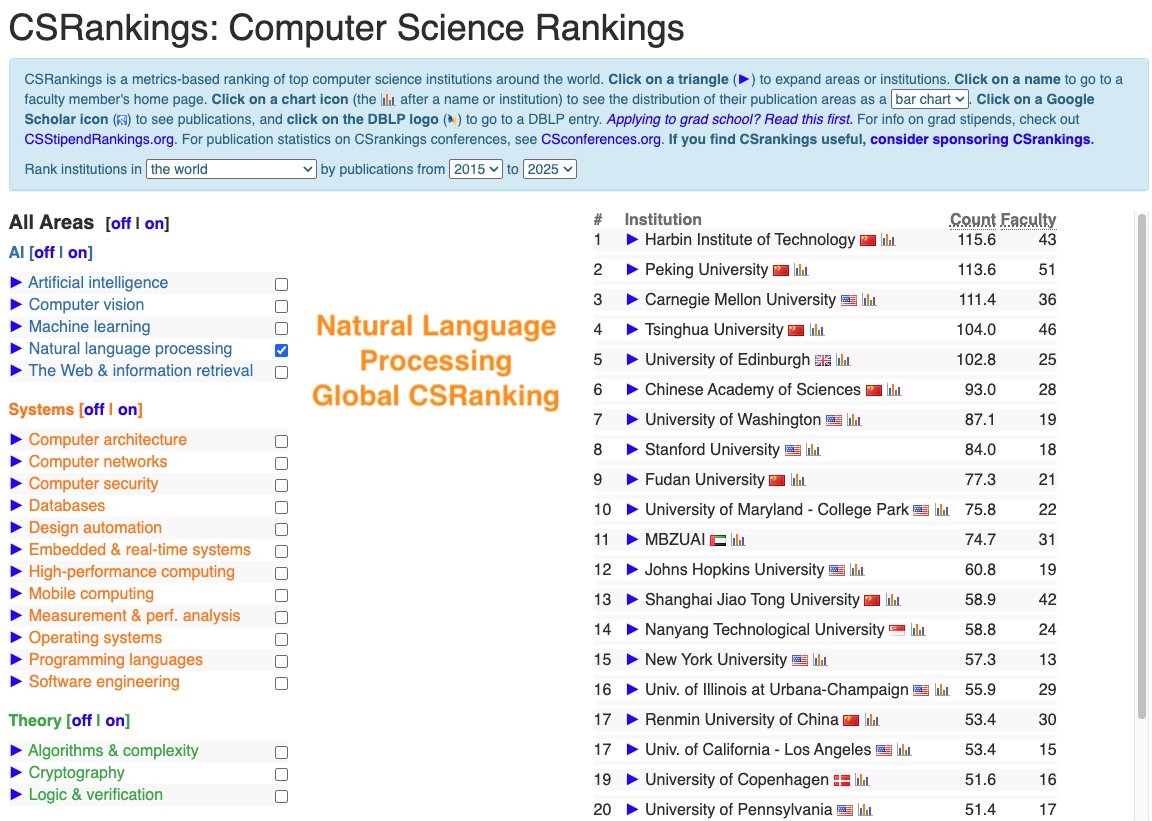
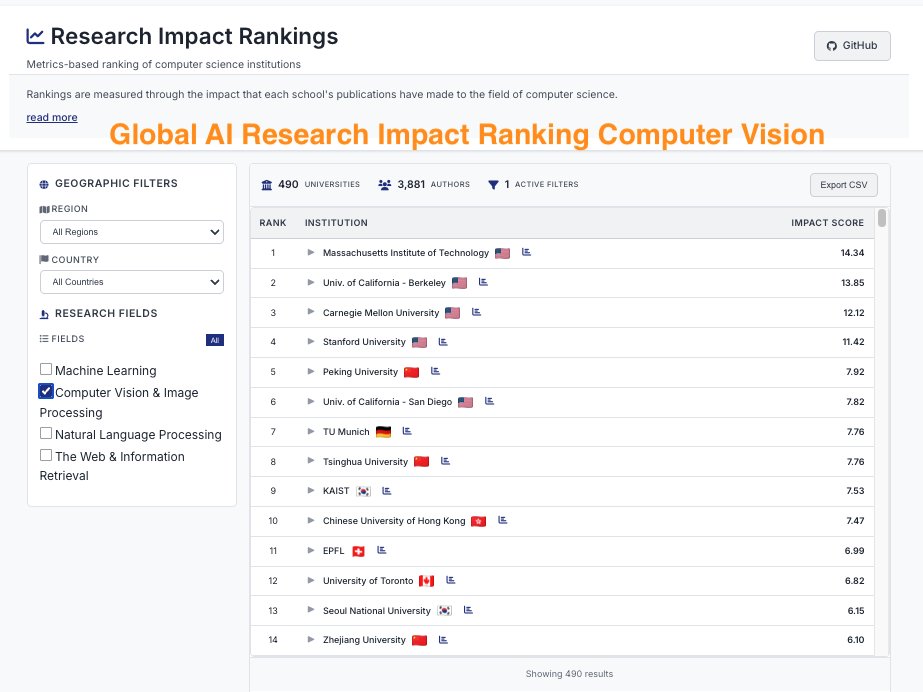
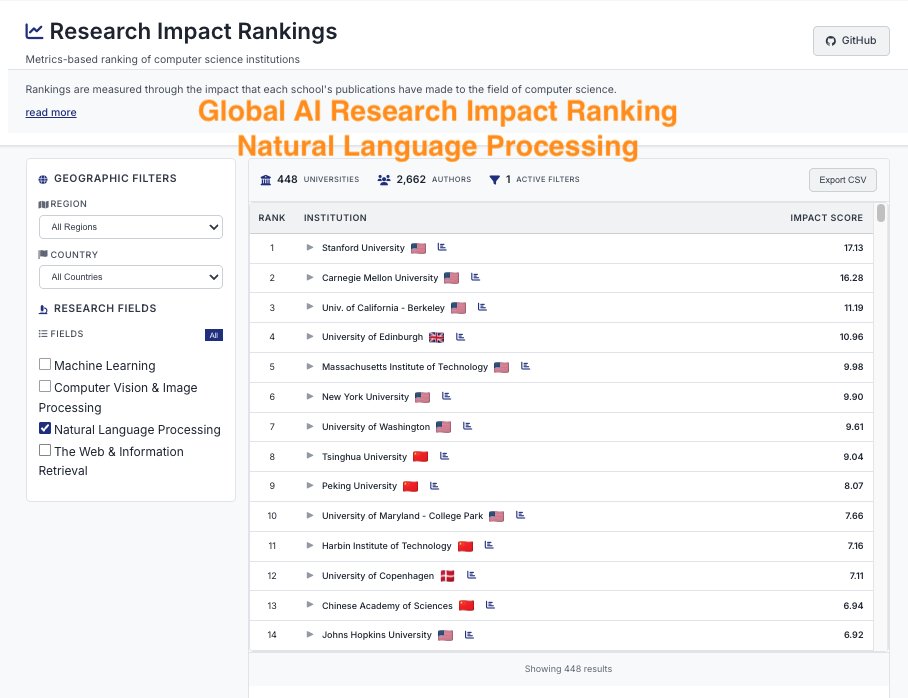

mech interp is surely a field in Kuhnian crisis alignmentforum.org/posts/StENzDcD…

¿Cómo manejan realmente los docentes el aula? Un nuevo estudio de Stanford analiza 1.652 transcripciones de clases usando IA y NLP para medir cómo los profesores usan el lenguaje para gestionar comportamientos y mantener el orden. Un avance enorme para observar estas prácticas a…


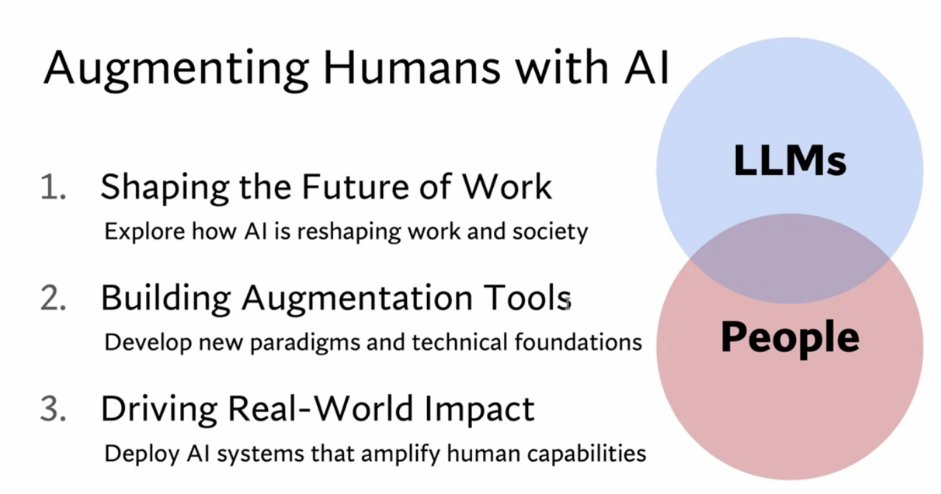
Inspiring Talk from @Diyi_Yang on the importance of developing foundation models to augment humans. Join us at Room Don Alberto 1!



Structured prompting is the easiest way to boost LM performance across benchmarks: +4–5% accuracy on average -up to +10–12% on reasoning tasks ~90% of gains come just from adding CoT and it cuts variance by ~2–4% so more stable outputs @DSPyOSS, once again.


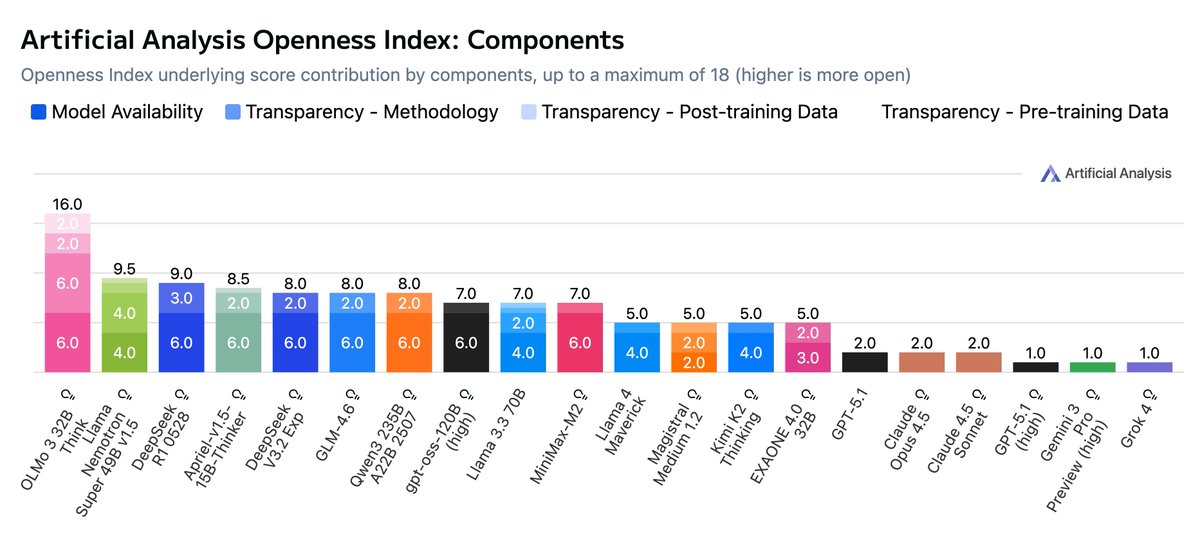
Introducing the Artificial Analysis Openness Index: a standardized and independently assessed measure of AI model openness across availability and transparency Openness is not just the ability to download model weights. It is also licensing, data and methodology - we developed a…

🚀DeepSeek V3.2 officially utilized our corrected KL regularization term in their training objective! On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning (arxiv.org/abs/2505.17508) See also tinker-docs.thinkingmachines.ai/losses It will be even better if they can…


🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…
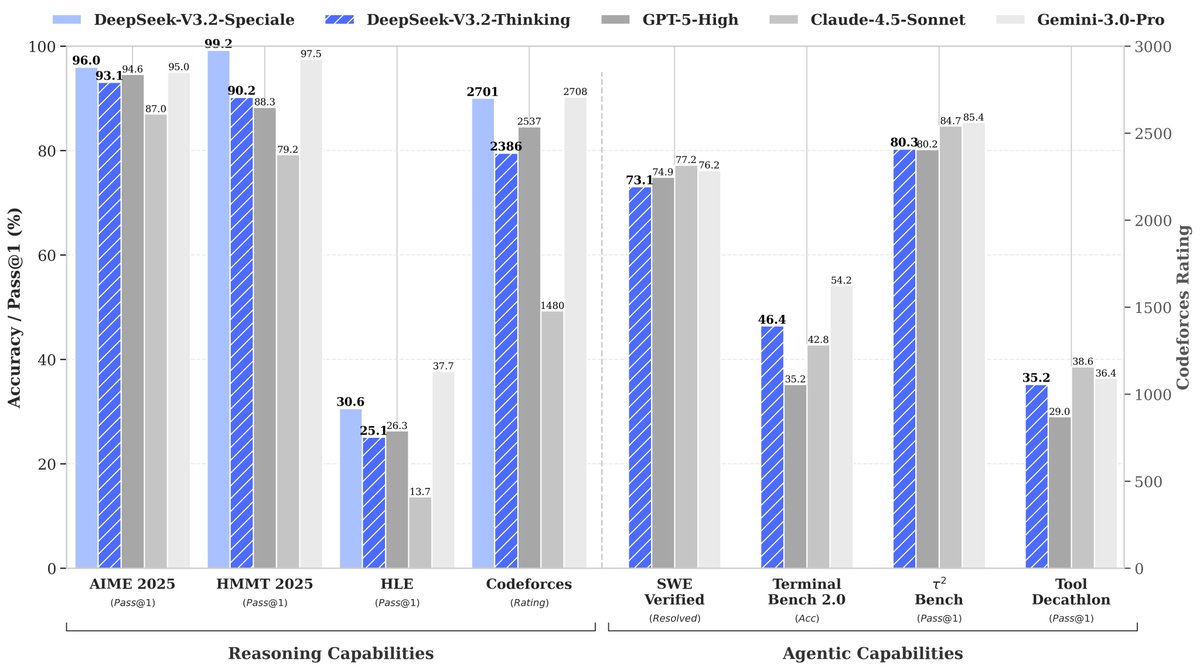
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…

Day 10 of becoming an LLM Engineer 🚀 Finished the CS224N lecture on Pretraining: 👉 subword tokenization (BPE) 👉 masked LM (BERT) 👉 span corruption (T5) 👉 pretraining → fine-tuning intuition 👉 decoder-only LM (GPT) 👉 in-context learning + chain-of-thought #AI #LLM #NLP

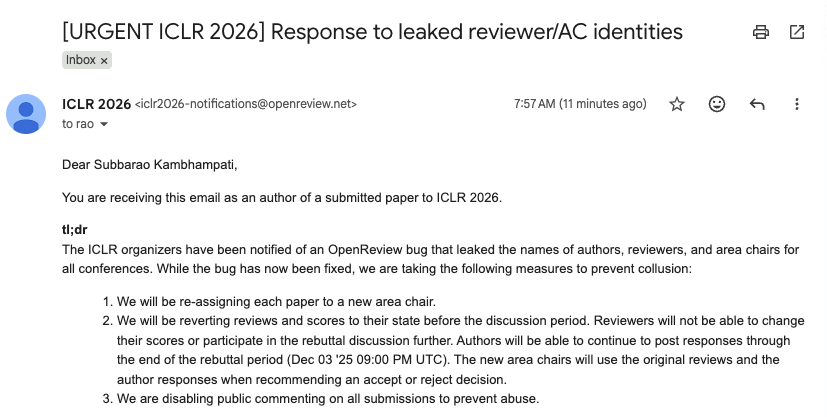
My heart goes out to @iclr_conf organizers who are putting up a valiant fight to restore review integrity in the face of the @openreview leak. Organizing conferences is always a labor of love, and doing so for mega AI conferences in the midst of a massive security leak is…





















































































































United States Tren
- 1. Chris Paul 8,827 posts
- 2. Pat Spencer 2,704 posts
- 3. FELIX LV VISIONARY SEOUL 10.8K posts
- 4. #FELIXxLouisVuitton 13.1K posts
- 5. Kerr 5,627 posts
- 6. Podz 3,322 posts
- 7. The Clippers 11.3K posts
- 8. Shai 15.8K posts
- 9. Seth Curry 5,039 posts
- 10. Jimmy Butler 2,663 posts
- 11. Lawrence Frank N/A
- 12. Hield 1,587 posts
- 13. Carter Hart 4,148 posts
- 14. #DubNation 1,439 posts
- 15. #SeanCombsTheReckoning 5,354 posts
- 16. Mark Pope 1,978 posts
- 17. #AreYouSure2 133K posts
- 18. Brandy 8,266 posts
- 19. Elden Campbell N/A
- 20. Derek Dixon 1,337 posts
Anda mungkin suka
-
 Andrew Ng
Andrew Ng
@AndrewYNg -
 Geoffrey Hinton
Geoffrey Hinton
@geoffreyhinton -
 Hugging Face
Hugging Face
@huggingface -
 Christopher Manning
Christopher Manning
@chrmanning -
 Andrej Karpathy
Andrej Karpathy
@karpathy -
 Ian Goodfellow
Ian Goodfellow
@goodfellow_ian -
 Stanford AI Lab
Stanford AI Lab
@StanfordAILab -
 Berkeley AI Research
Berkeley AI Research
@berkeley_ai -
 PyTorch
PyTorch
@PyTorch -
 Yann LeCun
Yann LeCun
@ylecun -
 Soumith Chintala
Soumith Chintala
@soumithchintala -
 Jeff Dean
Jeff Dean
@JeffDean -
 Sebastian Ruder
Sebastian Ruder
@seb_ruder -
 Demis Hassabis
Demis Hassabis
@demishassabis -
 Chris Olah
Chris Olah
@ch402
Something went wrong.
Something went wrong.