
你可能會喜歡
















Accepted papers for the Reliable ML from Unreliable Data workshop @ NeurIPS 2025 are now live on OpenReview! Thrilled to have @tatsu_hashimoto join @abeirami @charapod on our panel!


This is all covered in stanford's CS 336, by the way, for anyone needing a guide

During her @UN speech, HAI Senior Fellow @YejinChoinka called on the global community to expand the AI frontier for all. Here, she emphasized the need for investing in bold science, building public AI infrastructure, and prioritizing capacity-building: hai.stanford.edu/policy/yejin-c…


🤖➡️📉 Post-training made LLMs better at chat and reasoning—but worse at distributional alignment, diversity, and sometimes even steering(!) We measure this with our new resource (Spectrum Suite) and introduce Spectrum Tuning (method) to bring them back into our models! 🌈 1/🧵


Today is my 10 year anniversary of starting AI research. The first thing I worked on was sentiment analysis. Most young AI researchers today never have heard of sentiment analysis. Instead, modern sentiment analysis is studying the sentiment of AI model behavior (e.g. sycophancy)

Instruction tuning has a hidden cost: ✅ Better at following instructions ❌ Narrower output distribution ❌ Worse in-context steerability We built 🌈 Spectrum Suite to investigate this and 🌈 Spectrum Tuning as an alternative post-training method —
🤖➡️📉 Post-training made LLMs better at chat and reasoning—but worse at distributional alignment, diversity, and sometimes even steering(!) We measure this with our new resource (Spectrum Suite) and introduce Spectrum Tuning (method) to bring them back into our models! 🌈 1/🧵

Lot of insights in @YejinChoinka's talk on RL training. Rip for next token prediction training (NTP) and welcome to Reinforcement Learning Pretraining (RLP). #COLM2025 No place to even stand in the room.


I am a linguist who is celebrating in the LLM era, and constantly bragging about my past insights.

timelapse #1 (10hrs) >completed week #1 of CS224N >studied maths concept behind word embbedings >completed a server automation i had to do >coded and trained a CNN and a LSTM on the Flickr8K dataset to generate captions from a photo (learning purposes) >i also had a 2 hour…

Wrapped up an amazing #COLM2025 in good company, with @YejinChoinka @JenJSun @pliang279 @dsweld @Diyi_Yang 🍻🥳🎉


Many inconsistencies in Wikipedia discovered with the help of LLMs!

Excited to share our EMNLP 2025 (Main) paper: "Detecting Corpus-Level Knowledge Inconsistencies in Wikipedia with LLMs." How consistent is English Wikipedia? With the help of LLMs, we estimate 80M+ internally inconsistent facts (~3.3%). Small in percentage, large at corpus scale.

I'm feeling serious FOMO over COLM this week 😭 BUT the upside is that I'll be giving a guest lecture on pluralistic alignment in @Diyi_Yang's human-centered LLMs class at Stanford today🌲! Please reach out if you're in the area and want details :) web.stanford.edu/class/cs329x/

Throwback Thursday! Weaviate Podcast #85 with Omar Khattab (@lateinteraction) and Connor Shorten (@CShorten30)! This podcast covers: • What is the state of AI? • DSPy • LLM Pipelines • Prompt Tuning and Optimization • Models for Specific Tasks • LLM Compiler • Colbert or…


Nicholas Carlini man. That guy knows how to give a talk.
I suspect biases against prompt optimization derive from the community elevating RL post-training to a mythical status. The truth is that RL post-training is hard, and never effective without outstanding prompts. Prompt optimizers are cheaper and more effective in most scenarios.


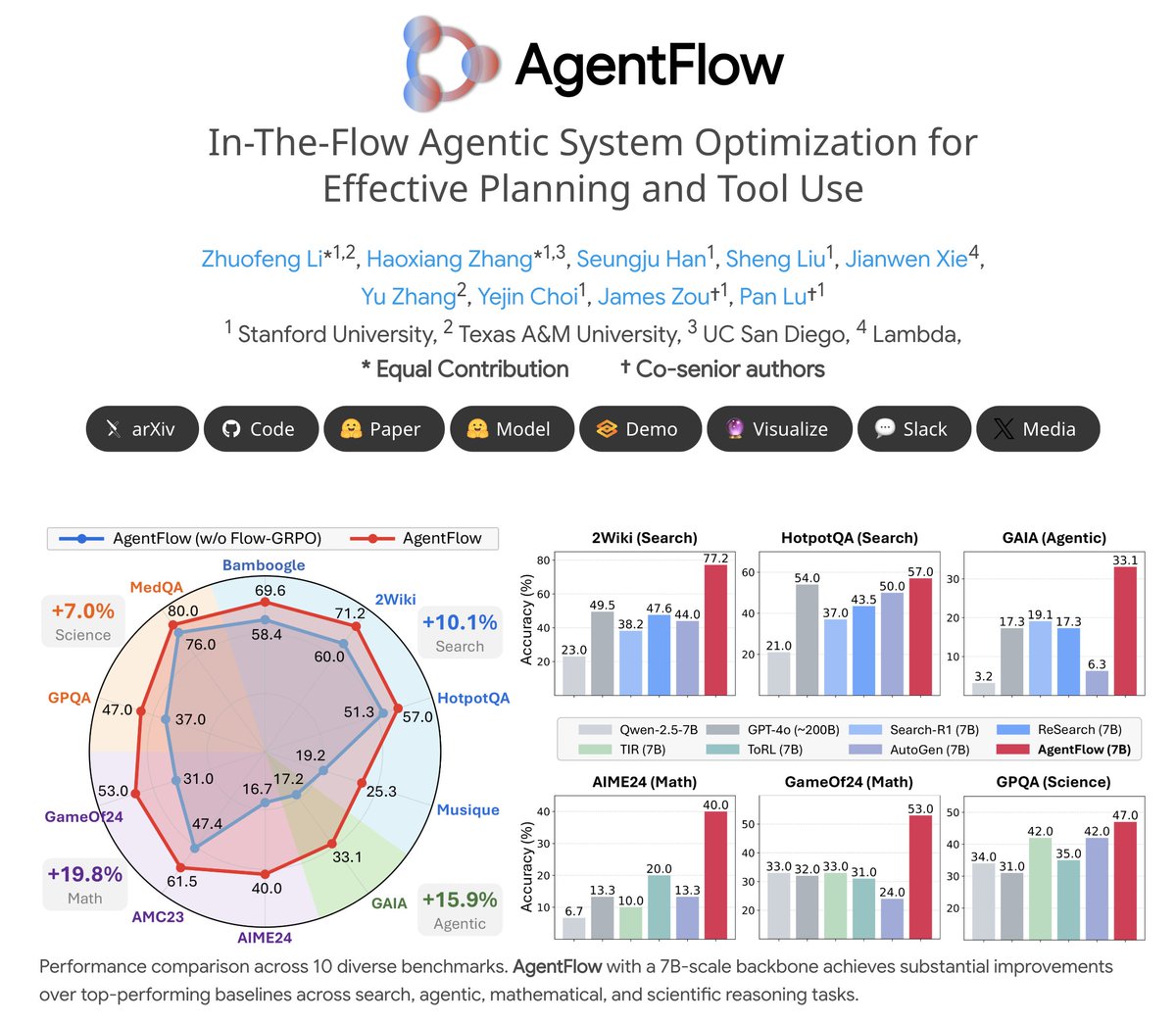
🔥Introducing #AgentFlow, a new trainable agentic system where a team of agents learns to plan and use tools in the flow of a task. 🌐agentflow.stanford.edu 📄huggingface.co/papers/2510.05… AgentFlow unlocks full potential of LLMs w/ tool-use. (And yes, our 3/7B model beats GPT-4o)👇…


Excited to share our EMNLP 2025 (Main) paper: "Detecting Corpus-Level Knowledge Inconsistencies in Wikipedia with LLMs." How consistent is English Wikipedia? With the help of LLMs, we estimate 80M+ internally inconsistent facts (~3.3%). Small in percentage, large at corpus scale.

“we find that interaction with sycophantic AI models significantly reduced participants’ willingness to take actions to repair interpersonal conflict, while increasing their conviction of being in the right.” Great work from @chengmyra1 and @stanfordnlp


We fought an uphill battle for 3 years. Glad to hear from OpenAI: "People are realizing that prompt optimization, which they thought 2 years ago would be dead, is further entrenched." "Really cool time in prompt optimizers, like GEPA." "To improve an entire agent over time."

ColBERT micro-models that “perform well with 250K parameters”. That’s 0.00025B parameters for the uninitiated 😂

✨ We're proud to release the ColBERT Nano series of models. All 3 of these models come in at less than 1 million parameters (250K, 450K, 950K)! Late interaction models perform shockingly well with small models. Collection: huggingface.co/collections/Ne… Model: huggingface.co/NeuML/colbert-…



















































































































United States 趨勢
- 1. D’Angelo 299K posts
- 2. Young Republicans 15.8K posts
- 3. #PortfolioDay 17.4K posts
- 4. Pentagon 110K posts
- 5. Politico 176K posts
- 6. Presidential Medal of Freedom 66.7K posts
- 7. Brown Sugar 21.4K posts
- 8. Angie Stone 34.7K posts
- 9. Big 12 N/A
- 10. Drew Struzan 30.1K posts
- 11. David Bell N/A
- 12. Scream 5 N/A
- 13. Black Messiah 11.2K posts
- 14. Venables 3,842 posts
- 15. Soybeans 5,761 posts
- 16. Milei 279K posts
- 17. NHRA N/A
- 18. Merino 16.2K posts
- 19. World Cup 355K posts
- 20. VPNs 1,560 posts
你可能會喜歡
-
 Andrew Ng
Andrew Ng
@AndrewYNg -
 Geoffrey Hinton
Geoffrey Hinton
@geoffreyhinton -
 Hugging Face
Hugging Face
@huggingface -
 Christopher Manning
Christopher Manning
@chrmanning -
 Andrej Karpathy
Andrej Karpathy
@karpathy -
 Ian Goodfellow
Ian Goodfellow
@goodfellow_ian -
 Stanford AI Lab
Stanford AI Lab
@StanfordAILab -
 Berkeley AI Research
Berkeley AI Research
@berkeley_ai -
 PyTorch
PyTorch
@PyTorch -
 Yann LeCun
Yann LeCun
@ylecun -
 Soumith Chintala
Soumith Chintala
@soumithchintala -
 Jeff Dean
Jeff Dean
@JeffDean -
 Sebastian Ruder
Sebastian Ruder
@seb_ruder -
 Demis Hassabis
Demis Hassabis
@demishassabis -
 Chris Olah
Chris Olah
@ch402
Something went wrong.
Something went wrong.